

monorepo (monolithic repository) 是一种项目架构(而不是软件架构或设计模式),是一种项目管理手段,简单的来说:一个仓库内包含系统的多个开发项目(模块,包),把所有相关的 package 都放在一个仓库里进行管理,每个 package 独立发布。
通过本博客,你将了解monorepo的概念,以及进行一次采用yarn workspace+lerna的monorepo方案的实践。需要注意的是,本博客并不包含npm版本发布实践的部分。
一点题外话:关于monorepo体系国内的资料其实比较少,我在写这篇文章的时候其实本来想的是快速看一点国内的资料就上手开始做,但发现国内相关的技术博客实在质量一般,没有一篇系统性的全面介绍,因此写下这篇博客也是希望能帮到后来想要快速上手monorepo架构解决问题的同学。
monorepo 辩经
来自yarn3 workspace文档中的一段话:
In short, they allow multiple projects to live together in the same repository AND to cross-reference each other - any modification to one's source code being instantly applied to the others.
虽然在一些原教旨主义看来,按项目拆分仓库、拆分npm包是天然且唯一的方案;但当不同仓库/项目的内容出现关联时,创建复杂的包引用和软连接始终不如直接把源码放在一起来的高效。
工程化的最终目的是让业务开发可以 100% 聚焦在业务逻辑上,而不是将精力分散到代码复用、依赖版本管理上,因此所谓的工程化思想只是手段,而不是目的。正所谓”不论黑猫白猫,抓到耗子就是好猫“,monorepo架构虽然有着Git版本管理困难、仓库臃肿、编译时间长等原教旨主义唾弃的问题,但在有些项目之间依赖紧密的框架内部它就是最好的方案。
正因如此,许多热门的前端项目如:React, Angular, Babel, Jest, Umijs, Vue 等都是采用的这种架构模式,monorepo架构使它们可以快速迭代、修改不同组件而不必等待依赖链更新。
monorepo的优点
除了上面提到了方便不同仓库/项目的内容出现关联时的软链接过程(交给包管理器自动完成),monorepo还有以下优点:
- 更容易统一项目配置和脚手架(如Git Hooks、ESLint、Prettier等)
- 同时为一系列包发版
- 维护库代码时不同项目之间的改动立刻生效
- 可以使用自动化工具生成CHANGELOG(如lerna)
你是否需要monorepo
还是那句话,还是那句话,没有银弹!没有银弹! 你需不需要使用monorepo完全取决于你自己的需求!但实际情况是,需要使用monorepo的场景,其害处(如编译时间增加、代码仓库膨胀等)远不足以让团队放弃这个方案,他们已经完全沉浸于monorepo所带来的开发体验了(如即时生效的改动)。 你需不需要使用monorepo完全取决于你自己的需求!但实际情况是,需要使用monorepo的场景,其害处(如编译时间增加、代码仓库膨胀等)远不足以让团队放弃这个方案,他们已经完全沉浸于monorepo所带来的开发体验了(如即时生效的改动)。
这里提供一个quiz,满足下面三个要求就说明你适合monorepo:
- 主业务流程和功能规模相对稳定,规模不太可能剧增
- 业务一般由单个团队维护,在多端之间的权限相对一致,涉及端规模比较可控
- 用户侧业务逻辑有变的时候,常对上线时间有强要求,因此最好变更范围易控,一次修改可多端生效
monorepo 实操
这里我们使用yarn的workspace机制和lerna来进行monorepo的管理,使用yarn workspace来管理依赖,使用lerna来管理npm包的版本发布,这是目前社区中最主流的方案,也是yarn官方推荐的方案,虽然有pnpm方案作为替代,但这里还是选用这个经典的方案。
在最后的上手操作中跟着步骤走,你将得到一个基于yarn3和lerna的monorepo仓库,同时管理react前端和koa.js后端项目。
什么是 worksapce
根据yarn3的文档,我们可知在yarn3中workspace是为了monorepo中多项目管理设置的yarn link(软链接)的语法糖,使用workspace使我们可以在所有子项目之间共享一份依赖,而不用单独安装。
除此之外,由于npm/yarn/pnpm都支持worksapce的功能,其实际上是一个定义在package.json中的协议,不同包管理器都支持这个协议,但其不同之处在于依赖管理的方式(扁平、pnpm或者pnp方式)。
需要注意的是,workspace与后面我们提高的lerna并不冲突,[lerna会尝试使用原生的workspace机制来管理依赖](#如何使用 lerna),这也为我们使用二者共同管理monorepo埋下了可能的种子。
workspace 协议
首先,我们要明晰有些词汇的含义(来源于yarn文档):
- 仓库(原文中叫project,为了避免混淆我这里就叫仓库了):你的整个目录,通常也是你的Git仓库所在地
- 项目(原文中叫workspace,同样是为了避免混淆):通常是packages/目录下的某个目录,也是实际的工作目录
- 项目树(原文中叫worktree):项目对应的目录树,列出了项目及其子项目(是的,项目也可以有自己的子项目,无限套娃,但这需要特殊的声明,不在本文的讨论范围内),一个仓库至少有一个项目和一个工作树,也可以有多个。
为了开始我们的monorepo之旅,我们需要在根项目(最外层的项目,即根目录下的package.json)中声明一个项目树,就像下面这样(当然后面讲的lerna会自动为我们生成):
{
"workspaces": [
"packages/*"
]
}为了维持workspace的特性,需要对workspace中的项目做一些限制或者说定义:
- 只能访问项目自己定义的依赖,而不能访问其他项目的依赖,即使存在在node_modules中
- 项目会优先访问本地依赖,如果可以满足要求就不会请求远程仓库
除了限制,我们还对worksapce有一些额外的语法支持,以满足monorepo的开发需求:
别名语法(
workspace:)- 通配符如
foo: workspace:*:这会在当前项目树中查找所有名为foo的包 - 其他别名如
foo: workspace:foo@*也是有效的,它们都会在发布时转化为有效名称 - 相对路径语法如
foo: workspace:../foo也是有效的,会根据对应的workspace进行寻找(适用于嵌套的情况) - *可以直接使用
yarn workspace <workspace> add <package>来添加当前工作目录下的其他包,会变成 ****workspace:^*的形式(推荐!)
- 通配符如
- 发布项目:包管理器将动态替换这些
workspace:依赖,但包管理器本身并不承担发布本身的工作,一般由其他方案如lerna或rush来承担
如何使用 yarn workspaces
虽然npm/yarn/pnpm都支持workspace,且都有几乎统一的workspace协议(定义在package.json)中,彼此的架构也都借鉴了老祖宗lerna,但语法上还是略有不同,大同小异。
这里我主要介绍yarn workspace的CLI语法和使用 (因为自己项目的技术选型是这个嘿嘿)
需要注意的是:在根目录运行yarn <command>会对所有项目都运行对应指令。(值得注意的是,在任何目录运行yarn install都会安装所有依赖)
yarn workspace <workspace> <command>:对指定的workspace执行指令yarn workspace <workspace> run <command>:对指定项目运行命令yarn workspace <workspace> add/remove <package> [-D]:向指定项目添加/删除依赖
yarn workspaces <command>:对所有workspace执行指令yarn workspaces run <command>:对所有workspace执行指令yarn workspaces info [--json]:打印依赖关系树
yarn add/remove <package> -W:忽略workspace协议中的依赖管理,直接在根目录安装项目依赖(适用于通用脚手架如eslint等)
什么是 Lerna
Lerna is The Original Tool for JavaScript Monorepos.
It is a fast, modern build system for managing and publishing multiple JavaScript/TypeScript packages from the same repository.
Lerna 是一个管理多个 npm 模块的工具,是 Babel 自己用来维护自己的 monorepo 并开源出的一个项目。优化维护多包的工作流,解决多个包互相依赖,且发布需要手动维护多个包的问题。
需要注意的是,lerna本身并不负责构建和测试等任务,而是基于npm scripts执行一套集中管理packages的自动化管理流程,并在这个统筹的层次进行优化(而并不深入到任务本身)。
它在此处的主要作用不是管理不同的packages(这些由包管理器如 yarn 负责),而是独立发布这些在一个repo中的packages。
Lerna在其官网列出了其特色功能:
- 链接其下不同的项目 链接其下不同的项目 (这一部分通常由包管理器完成)(这一部分通常由包管理器完成)
- 批量或独立对子项目运行指定脚本(如build、publish等)
- 独立发布某个子包而不是整个仓库,这是包管理器如yarn和pnpm无法完成的功能
- 快速构建(Super fast!),通过nx和缓存机制加速构建过程
- 零配置,易于上手,可以在现有的monorepo项目中无痛引入
- 漂亮的控制台输出和依赖可视化图
如何使用 lerna
通过简单的初始化,你可以在任何现有项目中引入lerna来管理你的monorepo项目:
$ npx lerna@latest init -y # npm官方已不再推荐全局安装包,而是通过npx使用最新版的包这个操作会做以下步骤:
- 将lerna添加到devDependencies中,并将private设为true(脚手架不需要发布)
- 在根目录生成一个lerna.json用于配置
- 生成./packages目录
- 配置npm/yarn/pnpm的workspace协议用于依赖管理。
由于现在的包管理器(包括npm)都自带了完整的workspace协议和依赖管理,lerna就不再使用其自带的lerna-bootstrap方案,而转投workspace方案,而bootstrap方案在v7版本已经废弃。
创建缓存
如果不进行任何配置,lerna运行任何命令都会执行所有的任务(即使没有任何代码发生改变),我们可以通过增加缓存配置来改善命令运行的时间。
$ npx lerna add-caching这个命令会通过一系列CLI提示指导你生成nx.json来配置生成过程的缓存。
版本管理
lerna version 的作用是进行 version bump,支持手动和自动两种模式。
- 手动确定版本:运行
lerna version后跟着提示一步步走 自动确定版本:自动根据
conventional commit规范确定版本(要求满足commit规范才行),命令:lerna version --conventional-commits- commit(scope):只更新对应scope版本
- 存在feat提交: 需要更新minor版本
- 存在fix提交: 需要更新patch版本
- 存在BREAKING CHANGE提交: 需要更新大版本
发布npm包
这是lerna最重要的功能之一,也是包管理器暂时无法替代的功能。
$ npx lerna publish --no-private以上命令会自动独立地发布仓库内未设为私有(private)的所有packages。
什么是nx
相信看过了上面的介绍,对反复提到的nx模块也感到了一丝好奇,lerna的众多功能包括任务优化(fast task scheduling & task pipelines)、构建缓存(caching)、可视化依赖(dependency visualization)等功能都依赖于nx的实现。那么,什么是nx呢?
Nx is a smart, fast and extensible build system with first class monorepo support and powerful integrations.
本文就不再深究nx是如何实现的,它为什么快这样的问题,只需要知道nx是一个新型的构建工具即可,更多内容会放在前端工具链-构建工具中。
nx的设计理念和vscode类似,作为构造工具本身已经足够快和优秀(就像vscode作为编辑器本身已经合格一样),支持workspaces等现代特性,还支持庞大的插件系统,让其更加强大。
除此之外,nx是一个独立的项目,lerna引用了nx(也就是说lerna的所有指令都会默认使用nx完成),但你也可以独立于lerna使用nx,为workspace机制带来nx的特性。
实战演练
我们已经了解了yarn workspace和lerna的基础知识,现在我们来实现一个基础需求吧:对一个原本的react前端+koajs后端的人员管理系统进行monorepo重构,它们本来就放在一个仓库里,现在我们对它进行monorepo改造。
为了方便演示,这里就用我之前做过的一个作业作为例子:KiritoKing/HUST-Kingsoft-2022。
这个项目的架构包含以下部分:
- fe/src:存放前端代码
- server:存放后端代码
- static:公共资源
当初为了共享一个脚手架以及方便启动,就把前后端放在了一个项目里,也算一个monorepo的雏形吧。
理清改造思路
在开始之前,我们要先理清我们的重构思路。我们要将这个仓库中的前端项目和后端项目打包为两个独立的模块,放在同一个仓库中管理:使用yarn workspace来管理依赖,使用lerna来管理npm包的版本发布。
除此之外,还有一个更重要的部分是,我们要理清工具之间的关系:yarn和lerna在这个过程中到底扮演了什么角色?
yarn和lerna这两个工具的互补性远远大于它们的互斥性,换言之就是它们可以配合运行得很好。
- 在功能上,它们是互补的:workspace用于管理依赖,lerna用于管理包的版本发布
- 在层级上,它们是依赖的:workspace是一个底层的工具,它负责实现处理包的安装、在项目之间创建符号链接,和在根目录和受控的项目文件夹下中分配模块;而lerna是一个更高级的工具,它在更高层级提供了monorepo的操作指令并对其进行优化(利用nx优化流程)
以及,最后一个原则问题:在二者功能重合时,应该使用yarn命令还是lerna命令?
实际上,在项目中我们一般不会遇到这个问题。因为yarn和lerna在职能上是有严格区分的,安装和管理依赖全权交由yarn负责,而其他功能则交由lerna负责。
虽然lerna的流水线功能可以由yarn基础地实现,但出于虽然lerna的流水线功能可以由yarn基础地实现,但出于**自定义性(如pipeline定义)和性能优化(如caching)**自定义性(如pipeline定义)和性能优化(如caching) 的角度来说,这些功能应优先交给lerna。 的角度来说,这些功能应优先交给lerna。
开始改造
首先我们先将整个项目clone下来,并使用yarn-v3进行依赖安装(如果corepack那一步出错可以参考我另一篇前端工具链-包管理器的文章)。
$ git clone https://github.com/KiritoKing/HUST-Kingsoft-2022.git
# 准备yarn-v3环境,要求node-v16.10+
$ sudo corepack enable # 要求管理员权限
$ corepack prepare yarn@stable --activate # 安装yarn-v3最新版
$ cd ./HUST-Kingsoft-2022
$ yarn install然后,我们引入lerna到项目中:
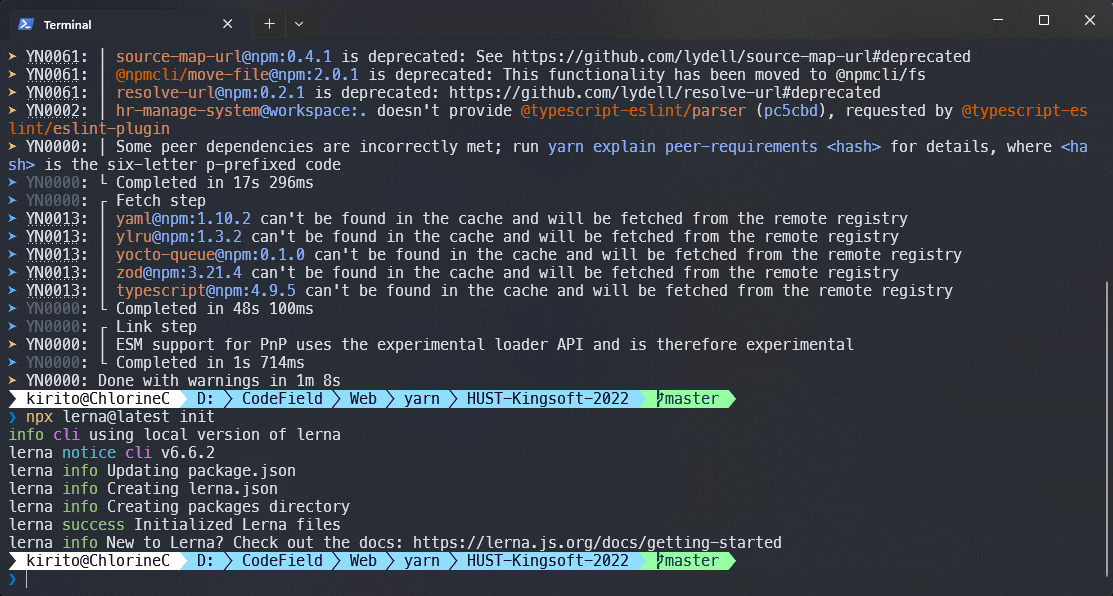
$ npx lerna@latest init
$ yarn install # 安装lerna如果以上步骤均成功,我们就可以看到以下画面:
然后我们需要对lerna.json进行一些修改,让它启用yarn workspaces(仅展示关键配置):
{
"npmClient": "yarn",
"useWorkspaces": true,
"version": "0.0.0"
}接下来,我们对其进行目录改造,也是最复杂的一步:
首先,我们需要创建子包:
# 我们有两种方法创建项目,以front-end为例
# 方法1:yarn方法
$ cd ./packages
$ mkdir front-end
$ cd ./front-end
$ yarn init -y # 初始化项目
# 方法2:lerna方法
$ lerna create front-end -y # 这相当于一个语法糖,推荐此方法然后我们需要将./fe/src的代码和其他文件转移到新目录中:
- 将src、webpack、static目录整个拷贝过来,然后删除原目录(服务端不需要)
- 参考根目录下的package.json修改项目里的配置文件
- 修改webpack配置./packages/front-end/webpack/webpack.common.config.js,删去变量
fe以及一切对其引用 - 将.bebelrc配置文件也放进新包中
- 由于原依赖中缺少了
@ant-design/icons,需要手动添加
$ yarn workspace front-end add @ant-design/icons- 最后运行构建依赖树并用webpack-serve运行
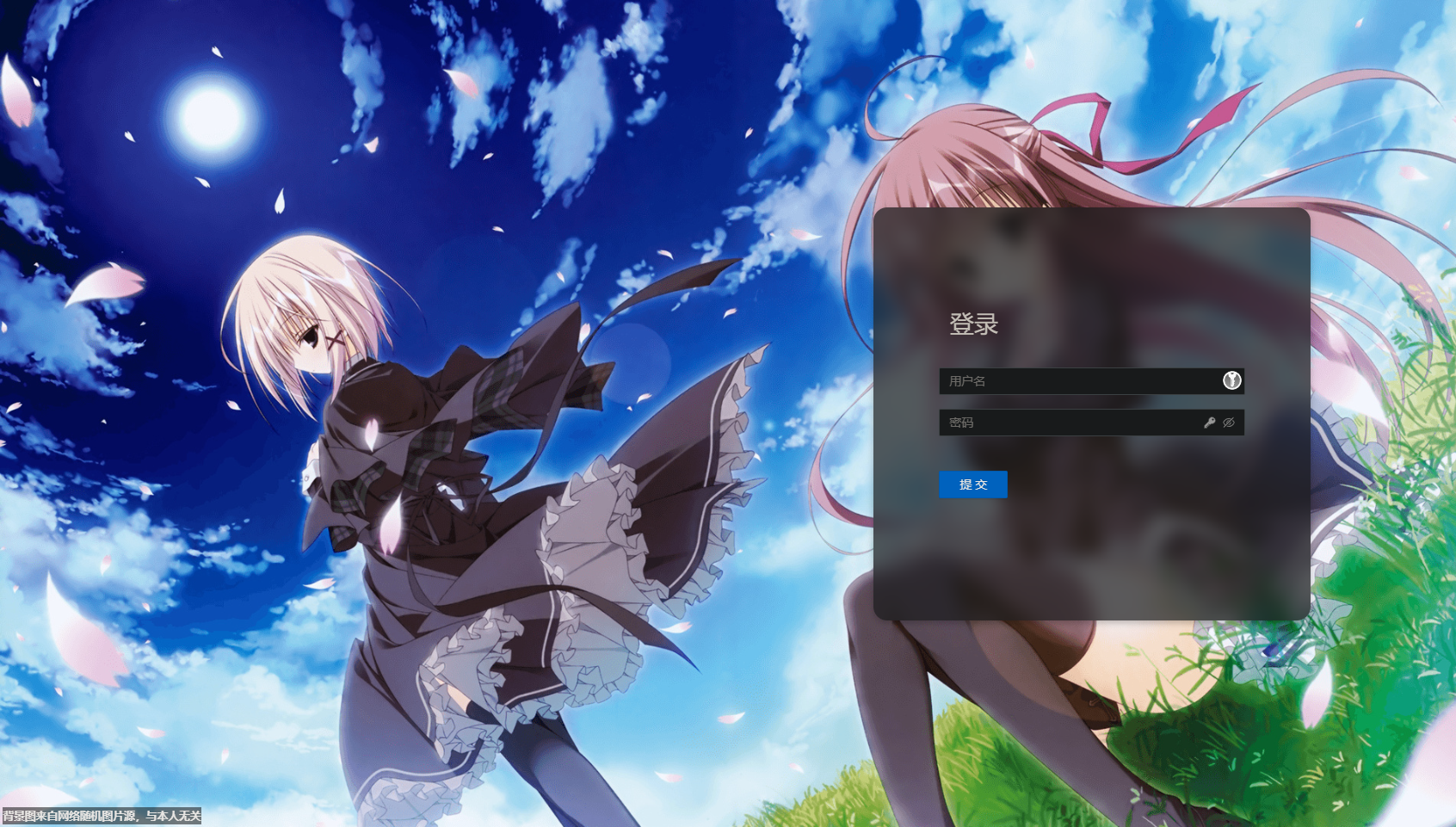
$ yarn install
$ yarn workspace front-end dev # 运行dev-server如果成功会看到登陆界面(背景图是随机的),但此时还不能正常登录,因为后端服务还没有运行。
好了,又到了喜闻乐见的抄作业时间,当下我的front-end/package.json是长这样的(我是用lerna create创建的),如果你运行不起来可以检查一下:
{
"name": "front-end",
"version": "0.0.0",
"description": "> TODO: description",
"author": "KiritoKing <[email protected]>",
"homepage": "https://github.com/KiritoKing/HUST-Kingsoft-2022#readme",
"license": "ISC",
"main": "src/index.tsx",
"proxy": "http://localhost:9001",
"directories": {
"lib": "lib",
"test": "__tests__"
},
"files": [
"lib"
],
"repository": {
"type": "git",
"url": "git+https://github.com/KiritoKing/HUST-Kingsoft-2022.git"
},
"scripts": {
"start": "webpack server --open --config ./webpack/webpack.dev.config.js",
"build": "webpack --config ./webpack/webpack.prod.config.js",
"test": "node ./__tests__/front-end.test.js"
},
"bugs": {
"url": "https://github.com/KiritoKing/HUST-Kingsoft-2022/issues"
},
"devDependencies": {
"@babel/core": "^7.19.3",
"@babel/preset-env": "^7.19.3",
"@babel/preset-react": "^7.18.6",
"@babel/preset-typescript": "^7.18.6",
"@emotion/react": "^11.10.4",
"@emotion/styled": "^11.10.4",
"@types/react": "^18.0.21",
"@types/react-dom": "^18.0.6",
"@typescript-eslint/eslint-plugin": "^5.41.0",
"babel-loader": "^8.2.5",
"classnames": "^2.3.2",
"clean-webpack-plugin": "^4.0.0",
"css-loader": "^6.7.1",
"html-webpack-plugin": "^5.5.0",
"mini-css-extract-plugin": "^2.6.1",
"style-loader": "^3.3.1",
"typescript-plugin-css-modules": "^3.4.0",
"webpack": "^5.74.0",
"webpack-cli": "^4.10.0",
"webpack-dev-server": "^4.11.1",
"webpack-merge": "^5.8.0"
},
"dependencies": {
"@ant-design/icons": "^5.1.2",
"@faker-js/faker": "^7.6.0",
"@reduxjs/toolkit": "^1.9.0",
"antd": "^4.24.2",
"axios": "^1.1.3",
"react": "^18.2.0",
"react-dom": "^18.2.0",
"react-redux": "^8.0.5",
"react-router-dom": "^6.4.2",
"react-use-cookie": "^1.4.0"
}
}
目录树长这样:
下面就练习一下吧,按照上面的方法对比较简单的server部分如法炮制,制作一个back-end包。(如果实在不行也可以看看monorepo分支)
需要注意的是,server部分由于逻辑有点写死了(早期作品理解一下),它在初次登录时会报错(可以在console看到),这时在back-end目录下创建一个server目录并把data移动进去就行。如果你有兴趣也可以帮我修一修bug
在你的工作完成后,使用admin+123456就可以登录系统了,界面如下:

至此,我们对其的monorepo改造已经基本完成,两个项目已经变成了独立的package,可以独立开发、维护、部署和发布。
善后和总结
通过上面的实战,我们大概可以知道,在monorepo仓库中:
- 每个项目都有自己的依赖,不同项目之间可以共用依赖,但必须在各自的package.json中分别声明
- 根目录下的依赖一般是整个项目的脚手架,如eslint, prettier之类(webpack一般会放在需要框架的项目中,不同项目之间如果需要共享配置则可以创建一个共享配置包(package))
但是,作为一个全栈应用,整个项目应该也是可以启动的,这里我们再做进一步的工作:在根目录package.json中添加一次性运行两个服务和编译全部服务的指令。
这里我直接使用了Copilot的代码稍加修改,使用了lerna运行脚本的能力:
{
"scripts": {
"dev": "npx lerna run start --parallel",
"build": "npx lerna run build",
"test": "npx lerna run typescript",
"clean": "npx lerna run clean --parallel",
"prepublish": "npx lerna run prepublish --parallel",
"prepare": "npx lerna run prepare --parallel",
"postinstall": "npx lerna run postinstall --parallel"
}
}这里解释一下为什么要用npx,因为yarn3的PnP到现在实际上还是实验性功能,出现兼容性问题在所难免,因此这里选择调用npx来调用lerna功能,详见这篇Issue
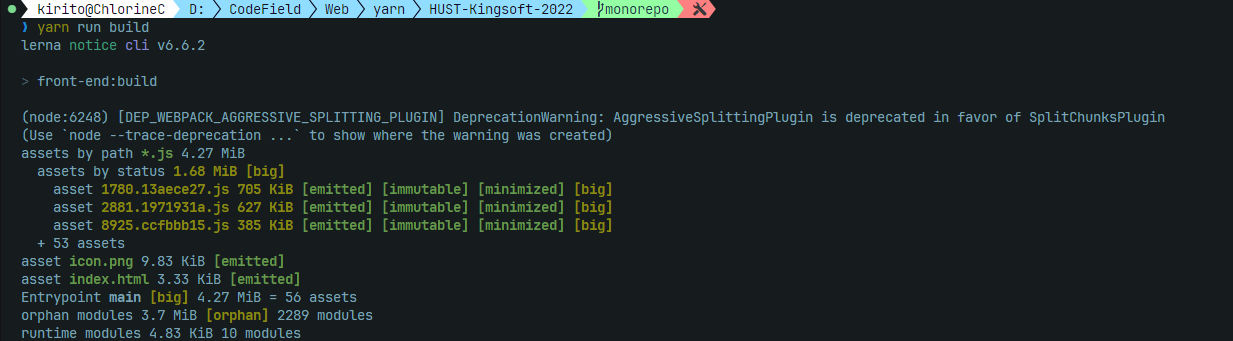
这下我们运行一下 yarn run dev,出现以下界面就代表成功了:
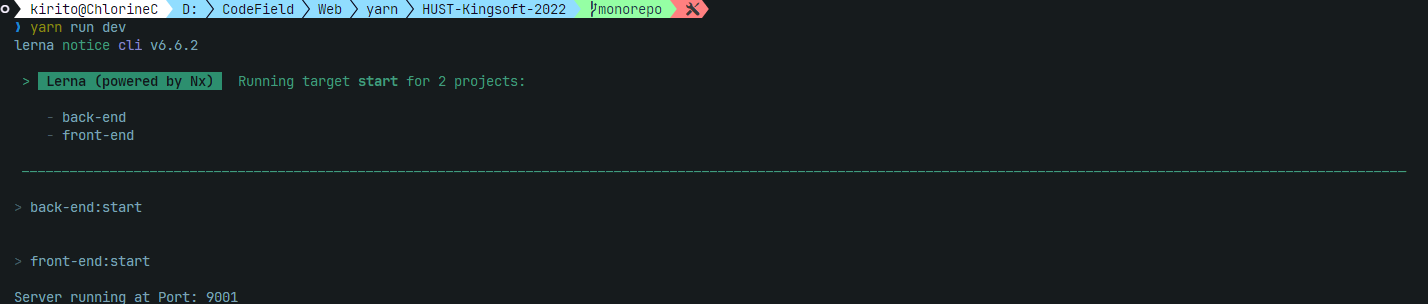
在运行 yarn run build 时我们发现lerna很智能地跳过了没有配置build的back-end包。
monorepo 最佳实践
如果你没有npm发版需求,那么npm/yarn/pnpm自带的workspace就可以满足你的几乎一切monorepo需求,但代价就是可能需要牺牲lerna或rush带来的一些额外功能,如指令自定义流水线(pipeline)等(yarn本身不支持拓扑排序规则运行脚本,lerna等构建工具则支持)。
在这一部分,我们将继续完善我们刚刚创建的monorepo仓库,如果你的练习还没有达到一条指令运行和构建整个项目,请修复这些bug (或直接从分支抄作业) 。完善后的仓库将拥有以下功能(当然这并不只是monorepo的最佳实践,而是前端工程化的最佳实践在monorepo的体现):
- Commit Lint功能:检查commit信息的规范性
- Git Hooks:在提交时实施代码检查
- 自动版本号更新:根据commit信息自动更新版本号
- 自动生成CHANGELOG:根据commit信息自动生成版本对应的changelog
- 项目独立和整体 Docker 部署(在另一篇博客中详细介绍,此处不再赘述)
- 生成一个共享配置包,管理项目的共享部分和通用接口类型
Commit 规范
Commit Message有什么用?为什么需要Commit Message?
这可能是很多Git初学者会问的问题。先不要嘲笑,在初学者的视野里,它一个人的练手项目,并不需要什么额外信息,他们可能甚至只是想找一个东西可以上传自己的代码,碰巧这个东西就是Git(Hub)而已,所以才会有push -f,才会嫌弃commit message是无用的。
一旦项目复杂了起来,需要版本和分支管理,或者多人协作,抑或需要配置自动化工作流(就像本文中的需求那样),commit message和Git规范就显得重要了起来。
只有有了统一的commit message规范,才能有统一的、自动化的工作流,提高团队效率。目前业界采用比较普遍的是 Conventional Commit 规范(约定式提交)。
约定式提交规范是一种基于提交信息的轻量级约定。 它提供了一组简单规则来创建清晰的提交历史; 这更有利于编写自动化工具。 通过在提交信息中描述功能、修复和破坏性变更, 使这种惯例与 SemVer 相互对应。(SemVer是一种版本管理规范,也是npm倡导的版本标准)
一份符合 conventional commit 规范的 commit message 应该长下面这样:
<type>[optional scope]: <description>
[optional body]
[optional footer(s)]
type:提交类型,用于为提交分类,决定更新哪个版本号(
MAJOR.MINOR.PATCH中更新哪个部分)基础类型
- fix:代表修复了某个bug,通常更新
patch - feat:代表在代码库中新增了一个功能,通常更新
minor - BREAKING CHANGE:在原有类型后面添加感叹号(!),如
fix!,需要更新major
- fix:代表修复了某个bug,通常更新
- 扩展类型(基于Angular约定):build(更改构建系统或外部依赖), chore(无法被归类的修改), ci(更改部署信息), docs, perf(代码性能优化), refactor(广义重构,不添加新功能或修复bug的代码修改), revert(版本回退), style(代码格式化,而非样式修改), test(修改或增加测试)
- scope:改动范围,声明改动了哪个部分的代码,在monorepo中通常为workspace,留空则默认为全局
- BREAKING CHANGE需要在脚注(footer)部分添加说明:
BREAKING CHANGE: ....
以下是一个示例:
# 包含了 ! 和 BREAKING CHANGE 脚注的提交说明
chore!: drop support for Node 6
BREAKING CHANGE: use JavaScript features not available in Node 6.
# 包含范围的提交说明
feat(lang): add polish language
如何自动规范 Commit Message
自动化任务可以从两部分入手:
- 通过一些向导或者shortcut快速生成符合规范的commit message
- 在真正commit的时候检查commit message格式,若不满足规范则不予通过以保证自动化流程
Commit 向导工具:Commitizen
使用commit向导工具(通常是cli向导)如Commitizen可以快速创建符合规范的commit message,这里介绍使用commitizen-cli工具生成commit message的方法,也便于后面直接利用相关工具直接生成conventional changelog。
在node-v12/14/16+npm-v6+的环境中,commitizen可以直接安装使用:
$ npm install -g commitizen cz-conventional-changelog然后我们可以对仓库做一些调整让它变得"commitizen-friendly",这样我们可以直接使用git cz调用commitizen,如果你不调整也可以使用npx cz调用。
只需要在根目录下创建一个.czrc的配置文件,其配置如下:
{
"path": "cz-conventional-changelog"
}然后运行git cz试试看,大概会得到下面的效果:

使用Git Hooks管理Commit规范
Git Hooks就是Git提供的Hooks(废话),众所周知Hooks一般指的是一个过程在不同的生命周期中暴露给外部的接口,以供外面获取或修改对应的数据,如React中组件的生命周期Hooks、Webpack的构建过程Hooks等,Git Hooks就是Git流程中的Hooks,如Add、Commit等都有对应的Hooks。
使用Husky管理Hooks
Husky是一个轻量级(6kb)、跨平台的Node工具包,用于更好地在Commit阶段注入Hooks。
It's recommended to add husky in root package.json. You can use tools like lerna and filters to only run scripts in packages that have been changed.
由于husky官方建议我们在根目录添加husky,因此这里我们直接在根目录使用yanr-v2+的安装命令(husky总是遵循包管理器的最新特性和最佳实践)
$ yarn dlx husky-init --yarn2 # dlx: Run a package in a temporary environment,类似于npx
$ yarn
# 手动安装
$ yarn add husky pinst -D
$ yarn husky install # 开启 Git Hooks
# 记得设置postinstall脚本为 husky install以上命令会自动帮你完成项目的配置,并安装依赖。
不同版本的husky之间差别较大,特别是v4和v5,这里使用的是v5版本,它利用了Git的现代新特性如core.hooksPath,因此使用方法有较大区别,原有的在package.json中的配置方法被废弃,必须使用命令行或修改.husky目录下的命令。
除此之外,对于yarn的配置也有较大区别,具体可以查看我分支中的.husky目录下的配置文件。(建议查看以作参考!)
如果要添加Husky规则,应该遵循以下规则:
- 先使用
yarn husky add <file> [cmd]写入文件 - 暂存刚刚的文件:
git add <file>
添加commit-lint
首先我们安装相关包:
# Install commitlint cli and conventional config
yarn add -D @commitlint/config-conventional @commitlint/cli然后我们在根目录下创建一个.commitlintrc.json配置文件(但凡配置文件我都倾向于使用json而不是js,为了避免奇怪的lint问题),内容如下:
{
"extends": [
"@commitlint/config-conventional"
]
}然后我们使用husky添加相关hook:
yarn husky add .husky/commit-msg 'yarn commitlint --edit ${1}'此时我们的hook就注册成功了,现在就只能提交符合conventional规范的commit了,如果违反了就会报错;而如果你按规范提交就可以成功提交(如使用git cz):
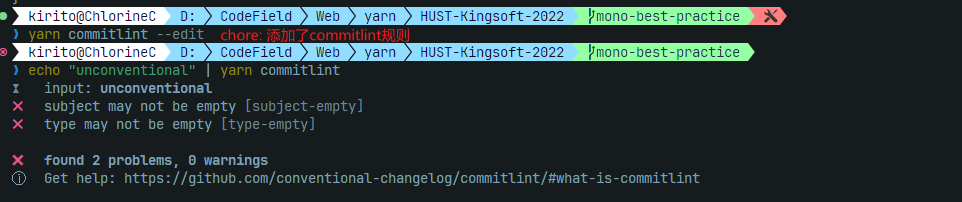
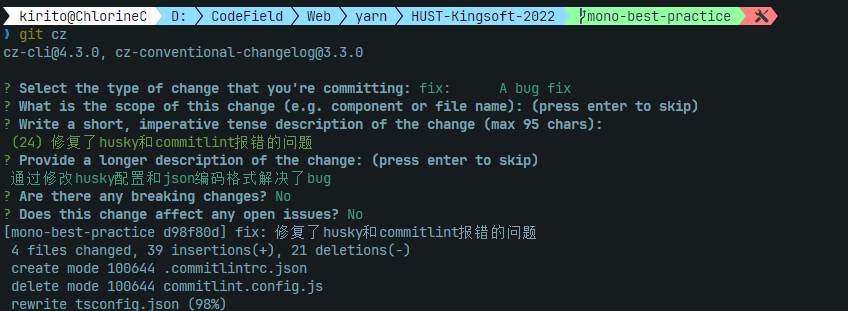
这里我卡在了一个奇怪的错误,JSON解析失败,后来问了GPT才发现是我的文档格式设成了UTF-16,改成UTF-8就正常了。最开始我还以为是Windows系统的锅。
至此,我们关于commit message的所有配置就完成了。
利用commit message
经历了有些波折的配置commit过程,是时候尝尝甜头了!我们的规范化的commit message能帮我做什么呢?
这里演示两个最基础的功能:
- 自动发布版本
- 自动生成日志(changelog)
这里我们直接借用lerna的自动版本管理功能(基于conventional commit messages)
$ lerna version --conventional-commits结果如下图所示:
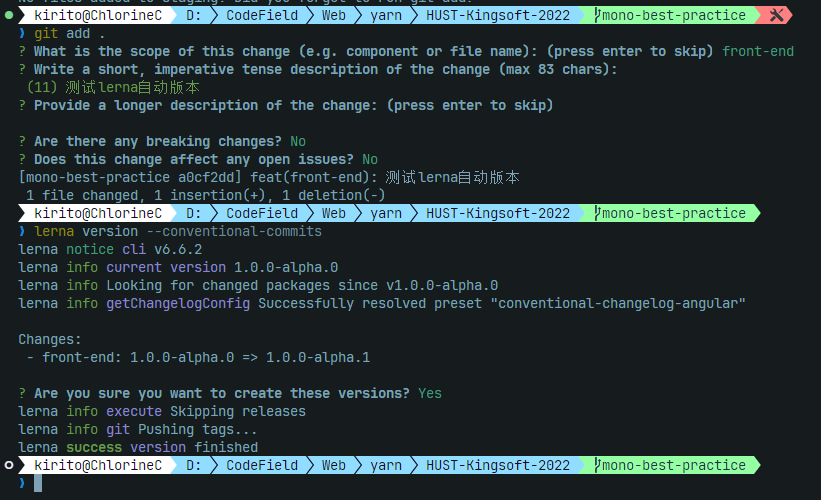
由图可知,这个命令帮我们做了这些事:
- 读取commit messages:从某个tag开始(记录版本时会在git历史上打tag,包括手动)寻找commit messages,并根据规则解析
- 如果找到需要更改版本号的commit,就在对应scope修改版本号(会询问)
- 在新commit打标签,并根据两个tag之间的commit message自动生成changelog
- 提交标签(tag和commit是有区别的),推送更新到npm(如果有设置)
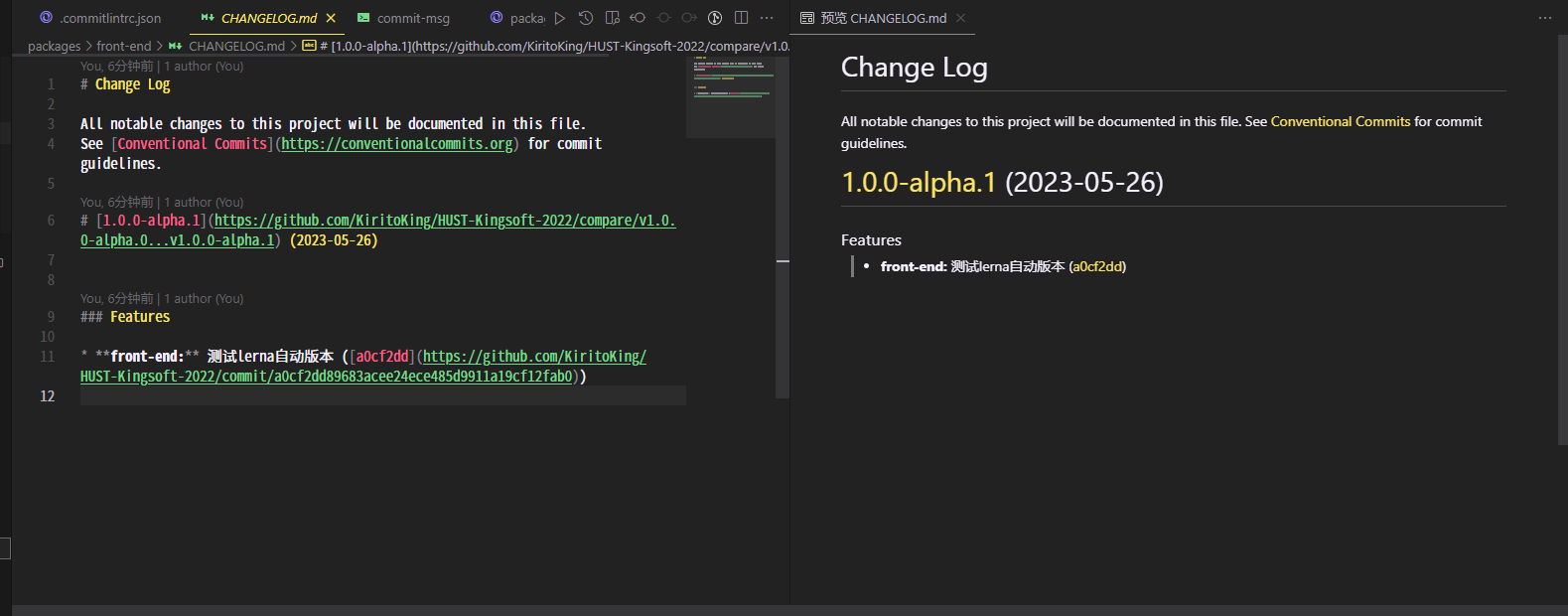
自动生成的CHANGELOG长这样:
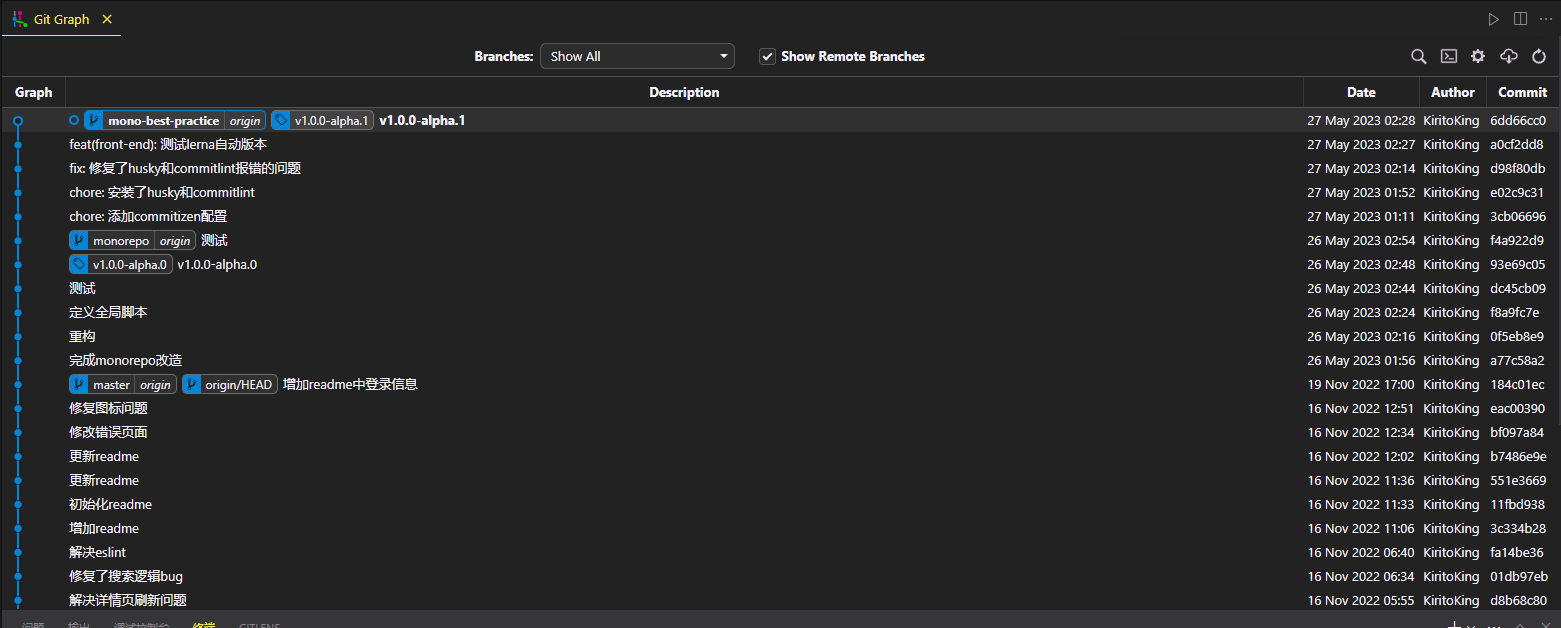
Commit 记录则长这样:
其他 Hooks
除了处理commit信息来完善提交、发版自动化流程以外,我们还可以添加其他hooks(借助husky),这里最重要的就是代码检查和测试了。
代码检查
我们可以使用pre-commit的Hook来实现提交代码检查:保证提交到git暂存区的所有代码都是符合规范的!
这里我们借用lint-staged和上文提到的husky快速实现git提交时代码检查的功能。
我们首先安装并添加lint-staged的hooks:
$ yarn add -D lint-staged然后对其进行配置,由于lint-staged支持在package.json中配置,就不新增配置文件了(多一事不如少一事)。除此之外,我们还要定义我们的lint脚本,由于我们之前的项目中已经有了eslint和prettier的配置(兼容配置也做好了),就直接使用就行了:
{
...,
"lint-staged": {
"*.js": "eslint --fix",
"*.ts": "eslint --fix",
"*.tsx": "eslint --fix",
"*.json": "prettier --write"
}
}注意:
- 数组内的元素是串行执行的
- 一定要做筛选,尽管eslint和prettier本身具有筛选机制,但这里不做筛选很可能报错
随便修改一点代码,用命令yarn lint-staged试运行一下:(可能报错,安装一下yarn add @typescript-eslint/eslint-plugin -D就好)

将这个hook注入进husky,修改.husky/pre-commit:
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
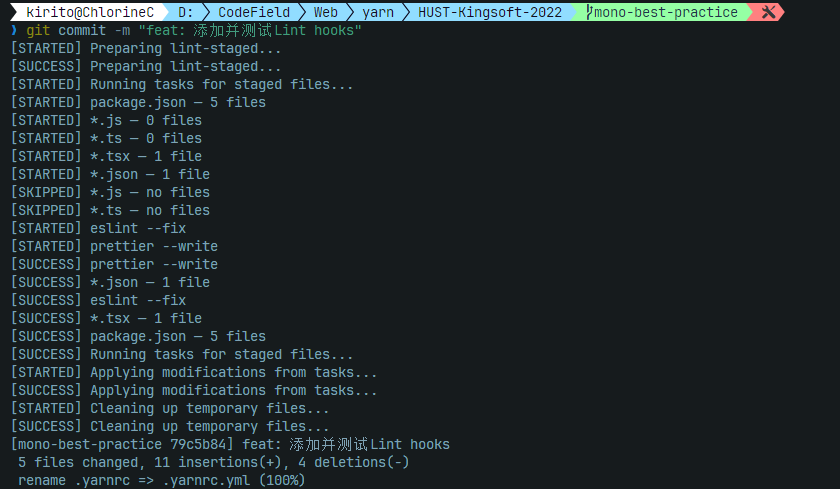
yarn lint-staged最后测试一下提交效果:
测试
与代码检查一样在pre-commit中添加测试命令即可,一般在代码检查后运行,这里就不再赘述。
参考资料
文档
- Getting Started | Lerna
- Workspaces | Yarn - Package Manager (yarnpkg.com)
- workspaces | npm Docs (npmjs.com)
- 约定式提交 (conventionalcommits.org)
- okonet/lint-staged: 🚫💩 — Run linters on git staged files (github.com)
博客
- 精读《Monorepo 的优势》 - 知乎 (zhihu.com)
- Monorepo 是什么,为什么大家都在用? - 知乎 (zhihu.com)
- monorepo的理解以及简单实现 - 掘金 (juejin.cn)
- Monorepo最佳实践之Yarn Workspaces - 掘金 (juejin.cn)
- 如何使用 Yarn Workspaces 配置一个 Monorepo JS/TS 项目 - 简书 (jianshu.com)
- lerna + yarn workspace 使用总结 - 掘金 (juejin.cn)
- 基于lerna和yarn workspace的monorepo工作流 - 知乎 (zhihu.com)
- 基于 Lerna 管理 packages 的 Monorepo 项目最佳实践 - 掘金 (juejin.cn)
- Yarn Workspace使用指南 - 知乎 (zhihu.com)
- Nx 介绍: 基于插件的单一代码库(Monorepo)构建系统_nx.json_AaronZZH的博客-CSDN博客
- [译]用 PNPM Workspaces 替换 Lerna + Yarn - 掘金 (juejin.cn)
- Git commit message 规范 - 掘金 (juejin.cn)
- lint-staged 使用教程 - 较瘦 - 博客园 (cnblogs.com)