
在之前的前端开发经历中,我几乎接触到的都是CSR(Client-Side Rendering)的SPA(Single Page Application)开发:
- 构建生成静态的空HTML和JS
- 使用前端路由实现页面跳转(实际上是JS切换渲染组件)
这样的架构的优势是简单易懂,不需要后端适配,但缺点也是显而易见的:
- 由于CSR架构的HTML是一个空的div,在接受到JS后才开始渲染内容,这对于爬虫来说就相当于一个空网页(虽然后续爬虫也进行了优化)
- CSR需要拿到JS后才会开始加载,且在JS加载完后才能显示内容,这对冷启动是很不友好的
因此,引入SSR就是为了优化上述问题。
渲染模式的变迁
要理解SSR与其他方式有什么不同和为什么需要SSR,我们需要了解整个Web开发和渲染的历史。
古神时代:全知全能
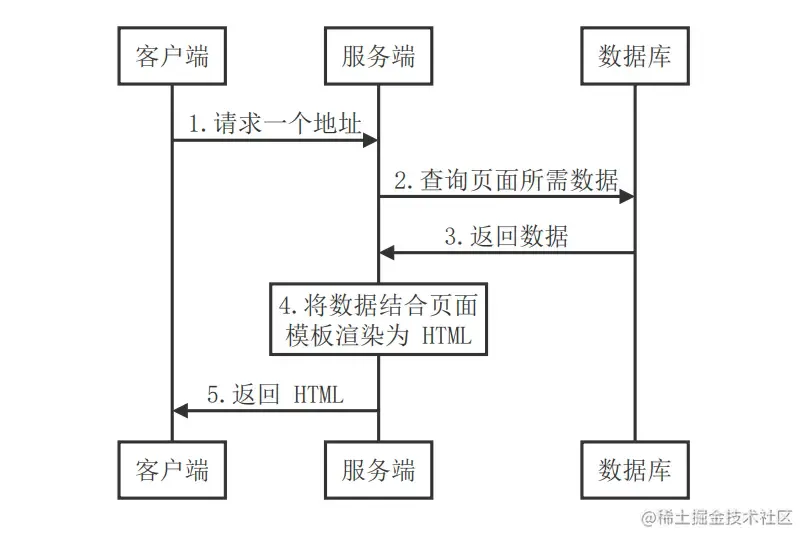
在古早Web时代,那个PHP和ASP一把梭的时代,是没有前端和后端的区分的,Web开发者一手负责后台数据库交互,一手负责直接在后台直接写好HTML传到浏览器上渲染,这就是所谓“服务端渲染”(Server-Side Rendering),即在服务端就生成了完整的HTML,前端只需要负责渲染,什么都不需要做。
现在我们仍可以对古神的操作用express进行拙劣的模仿:
const express = require('express');
const app = express();
app.get('/', (req, res) => {
res.send(`
<html>
<head>
<title>hello</title>
</head>
<body>
<h1>hello</h1>
<p>world ${Date.now()}</p>
</body>
</html>
`);
});
app.listen(3001, () => {
console.log('listen:3001');
});我们直接在服务端生成了可以直接运行的HTML,客户端接收到HTML后也不用对使用JS加载页面,直接渲染即可。这种模式下,前端显示的HTML页面可以看作对服务端状态某一时刻的切片,一旦生成就不再改变。
中古时期:身首异处
而随着Web生态的逐渐壮大,这种一把梭的模式慢慢地不能满足更复杂的需求了,在业务上逐渐分化出了前端和后端(虽然实际负责工作的人可能并没有分离)。
- 前端负责数据呈现和用户交互,从后端获取并返回数据,并承载一些不需要持久化的逻辑实现
- 后端负责向前端提供API,并负责后台数据库的交互
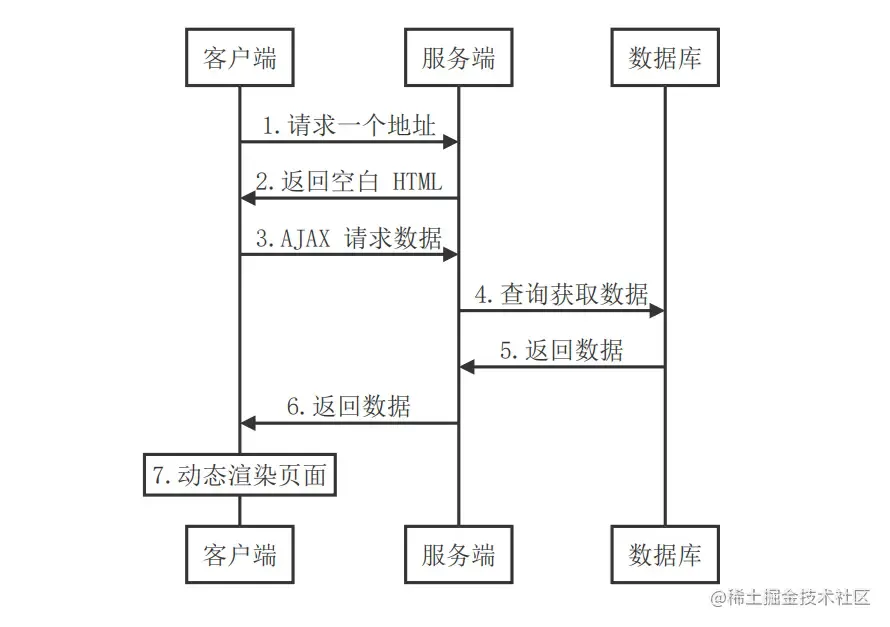
这个时候已经有了现代化的雏形,即传到前端的HTML并不包含完整的数据,在用户得到HTML后仍需要使用JS和XHR请求数据填充,如古老的网页聊天室这种即时性较强的应用。
现在仍有很多简单Web应用使用的是这种传统的JS方案,像传统jQeury就是在这种模式下的巅峰之作,它现在仍能满足很多简单的前端需求。
我们仍使用express对古代进行拙劣的模仿,通过express构建了一个简单API(虽然偷懒放在了一起还用了ES6语法),并将调用接口的返回值刷新在了页面上。
const express = require('express');
const app = express();
app.post('/api', (req, res) => {
console.log(req.body);
res.send({
time: Date.now(),
});
});
app.get('/', (req, res) => {
res.send(`
<html>
<head>
<title>hello</title>
</head>
<body>
<button id="btn">Click Me!</button>
<div id="container"></div>
<script>
const btn = document.getElementById('btn');
btn.addEventListener('click', () => {
fetch('/api', {
method: 'POST',
})
.then((resp) => resp.json())
.then((data) => {
const div = document.getElementById('container');
div.innerText = JSON.stringify(data);
});
});
</script>
</body>
</html>
`);
});
app.listen(3001, () => {
console.log('listen:3001');
});
近现代:矫枉过正
随着Web越来越火,需要承载越来越多的功能,前端开发也随之大火。
为了管理越来越复杂的项目和需求,一时间各种前端开发解决方案如雨后春笋般涌现,如react、vue等。这些框架帮助开发者更好地管理项目。
- 前端灵活性极强,由于完全依赖JS渲染,可以脱离后端URL限制更新页面内容,跳转和响应速度快
- 前端工程组织更灵活,可以更方便地组件化
但它们都有些过分强调前端的作用,都采用了客户端渲染的方案,即整个项目编译后只会生成一个空的index.html和若干JS文件用于加载应用,对于后端而言就只有一个单路径,完全忽略了后端URL的定位作用。
如下图所示,我们可以看到CSR应用请求的URL只会返回一个空的div标签,完全使用JS来加载内容,忽略了HTML本身的呈现作用,在复杂场景下可能有数秒的白屏加载等待时间。
当下:拨乱反正
正所谓历史是一个圈,随着React等框架的普及,CSR的缺陷也逐渐暴露出来,如SEO无法读取、首屏加载速度慢等,SSR也逐渐回到了大众视野中。
然士别三日,当刮目相待,归来的SSR结合了过往的SSR和CSR,成为“新物种”,我们叫它 “同构渲染”。
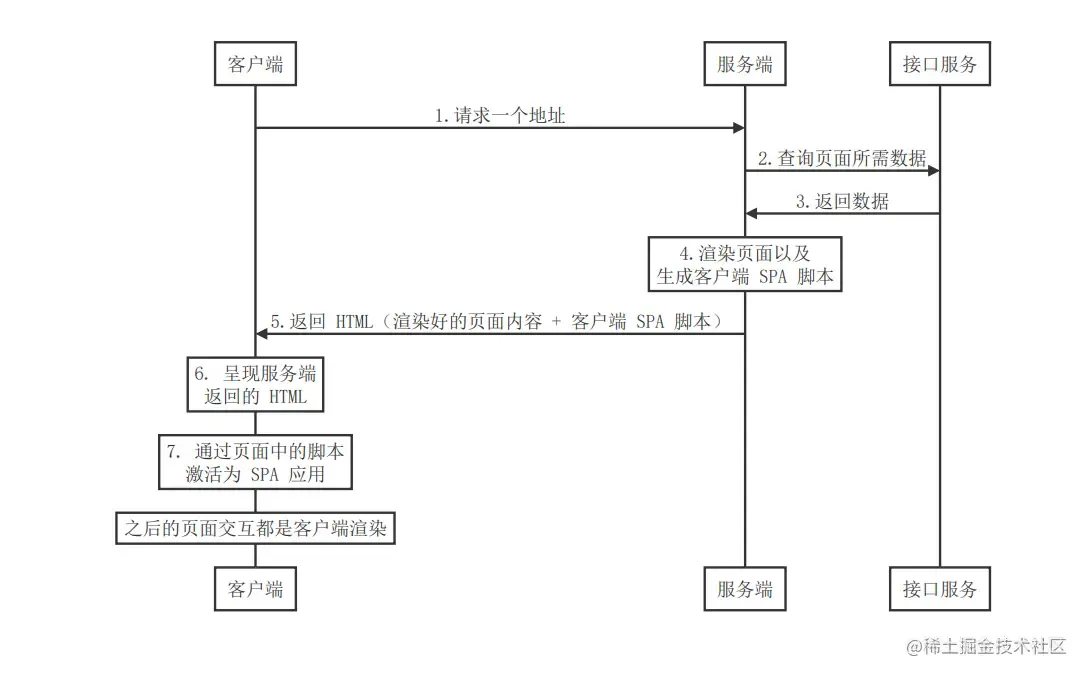
所谓同构,就是在SPA应用的基础上(这里默认同构应用也是SPA),同一份代码,我们在服务端执行一次,生成首屏HTML和CSR脚本;再在客户端执行一次,将应用交互所需的数据、事件等绑定到HTML上,完成应用的加载,后续仍是传统SPA应用的加载模式。
在新的“同构渲染”架构下,所谓的SSR其实是传统CSR+SSR的模式,即服务端先渲染一部分,客户端再渲染一部分。
- 客户端发起HTML请求
- 服务端收到请求后渲染首屏HTML,生成CSR资源,发送到客户端
- 客户端接收到HTML后渲染首屏内容,并在随后接收到JS文件后开始CSR过程
- CSR过程完成后应用完全加载完毕
然而,同构架构也有自己的缺点:
- 开发复杂,Node环境中不能操作DOM,在开发生态上要仔细甄别
- 同构架构复杂,特别是如何在网络环境中保持服务端和客户端同构是技术难点
- 需要维护Node服务端,且由于需要在服务端加载部分应用,应考虑服务端负载问题
因此,SSR也不是银弹,不是所有应用都适合无脑上SSR。
为什么需要同构
这个问题的背景和当年的蛮荒时期已经不同了,现在是前端高度工程化,各种框架大行其道的大前端时代。
我们可以稍稍翻译一下这个问题,即为什么一定要在服务端和客户端运行同一份代码呢?我们完全可以借鉴传统C/S模型,后端渲染后端的,前端渲染前端的,互不干扰,还不用考虑两边如何保持一致。
不妨假设用React构建了一个经典的SPA网页,我们要用SSR来处理这个应用,要怎么办呢?
在首次加载时,服务端渲染骨架和生成JS,返回给前端
- 过程中由于前端工程中使用了局部状态和全局状态,服务端不得不维护同一份状态来保证结果的正确性,也就是前后端的状态是复用的
- 在后续请求中,后端要接收来自前端的路由请求,并映射到自己的后端路由上,也就是说前后端的路由也是复用的
当前后端像这样有大量代码可复用时,双方使用同一份代码就有了很大意义,也就是说我们需要同构,让同一份代码在不同端做不同事,减少重复的工作和规避可能出现的错误,不用在前端组件框架和后端模板之间来回切换。
现代SSR和CSR的下性能对比
在C端页面上,SSR用作复杂应用的首屏加载速度优化可以显著提升留存率。
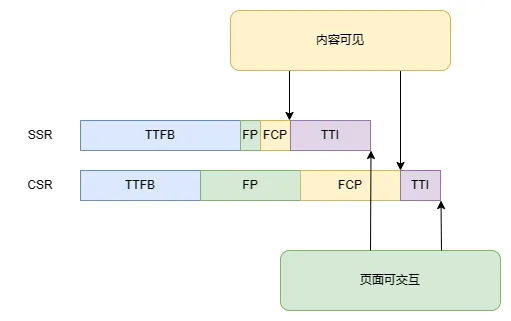
首先,我们要理解一些基础网页性能指标:
- TTFB(Time To First Byte):从点击链接到收到第一份内容响应的时间(网络响应时间)
- FP(First Paint):对用户显示任何画面响应的时间(用户得到响应的时间)
- FCP(First Contentful Paint):用户请求的内容可见的时间(首屏渲染时间)
- TTI(Time To Interactive):页面变得可交互的时间(应用加载时间)
SSR可能在TTFB上比CSR更慢,因为服务端需要渲染和准备当前请求的HTML,而CSR只需要直接传HTML和JS即可;
但后续FP和FCP都会显著快于CSR,因为服务端本地渲染HTML会比客户端渲染更快,且客户端拿到HTML后就可以立刻渲染而无需等待JS加载完成。
React中SSR实现
CSR数据模型
由于现代SSR实际上是SSR+CSR的混合模式,因此在理解SSR之前我们应先理解CSR应用是如何加载和运行的。
在理想情况下,React的函数组件应该是纯函数,即具有不变性(immutable)和稳定性(stable)的特征:
- 不会修改不是自身创建的数据(props)
- 渲染结果是稳定的,相同的输入(props+state)一定得到相同的输出
因此,我们可以把React的CSR数据流看成 “瀑布模型”:
- 应用中的数据流(包括状态和回调函数等)可以看作流动的水,它们在组件(瀑布的阶梯)间从上到下单向流转
每个组件都拥有自己的
state和props,接收上一级的props,向下一级传递自己的state和propsstate就像水源,是产生数据的地方props就像水管,是接收和传输数据的地方
- 当某个组件的状态发生改变时就像舀了一瓢水到某个结点中,这些水会依次流经其下游的所有结点,更新这些结点

React内置实现:脱水和水合
在理解了CSR的瀑布模型后,我们把抽象的“数据流”想象成水,就可以理解脱水(dehydrate)和水合(hydrate),以及同构在服务端和客户端分别做了什么工作。
我们可以接着“水”这个比喻,将SSR模型想象成“三体人模型”。

- 喝水(render):服务端渲染HTML,将React组件树渲染成实际的DOM树,毕竟要先有水才能脱水
- 脱水(dehydrate):脱去不必要的部分,以便于网络传输(实际上是仅部分加载),类似于三体人在乱纪元脱水成“人干”来维持生命
- 水合(hydrate):在客户端收到HTML和JS后,在骨架HTML的基础上还原剩下的部分,类似于三体人在恒纪元到来时“浸泡复活”
服务端渲染——喝水和脱水
React在react-dom/server中提供了renderToString()方法,这个方法可以将React组件树渲染成真实的DOM树,并以HTML形式表示。

计数器例子渲染出的HTML
除了生成DOM树外,服务端在首次渲染时还会进行数据初始化、异步请求等操作,最终得到一个完整的“静态”页面(不可交互)。
需要注意的是,所谓“喝水”和“脱水”实际上是一起进行的,hydrate通过仅执行组件生命周期的前几个周期实现了组件的初始化渲染。
客户端渲染——水合
⚠️React18中,由于引入了新的并发机制(concurrent),我们改用react-dom/client提供的hydrateRoot,它对应createRoot,正如hydrate对应render一样。
在客户端,React同样提供了hydrate() 方法来将拿到的骨架HTML还原为“有血有肉“的状态。
// client.js Example
import React from "react";
import App from "../components/App";
import { hydrateRoot } from "react-dom/client";
hydrateRoot(document.getElementById("root"), <App />);上面这个简单的例子实现了简单的前端还原,它通过在SSR模板中加入<script>引入,来实现在每次HTML加载后都运行水合过程来加载SPA。
全流程
- 首次访问时,后端路由根据URL选择和渲染组件,初始化数据和相关状态,根据模板生成HTML回传给浏览器
- 浏览器加载HTML,用户可以第一时间看见页面内容
- 浏览器按照顺序加载其中的JS资源,最终完成整个SPA的加载
⚠️需要注意的是,当**hydrate**过程发生错误,如初始数据不一致或DOM树不一致等,将放弃预渲染的HTML而完全回落到CSR,这是会使SSR完全失效的恶行BUG,同构开发过程中请特别注意数据的一致性。
组件在SSR和CSR中的区别
面向SSR的组件和面向CSR在本质上的区别是SSR组件实际上有两个加载周期,而在SSR周期中不能使用浏览器能力。
组件生命周期
SSR渲染过程中的组件生命周期是不完整的,一般只执行constructor, getDerivedStateFromProps和render,也就是说只对组件进行初始化和渲染。
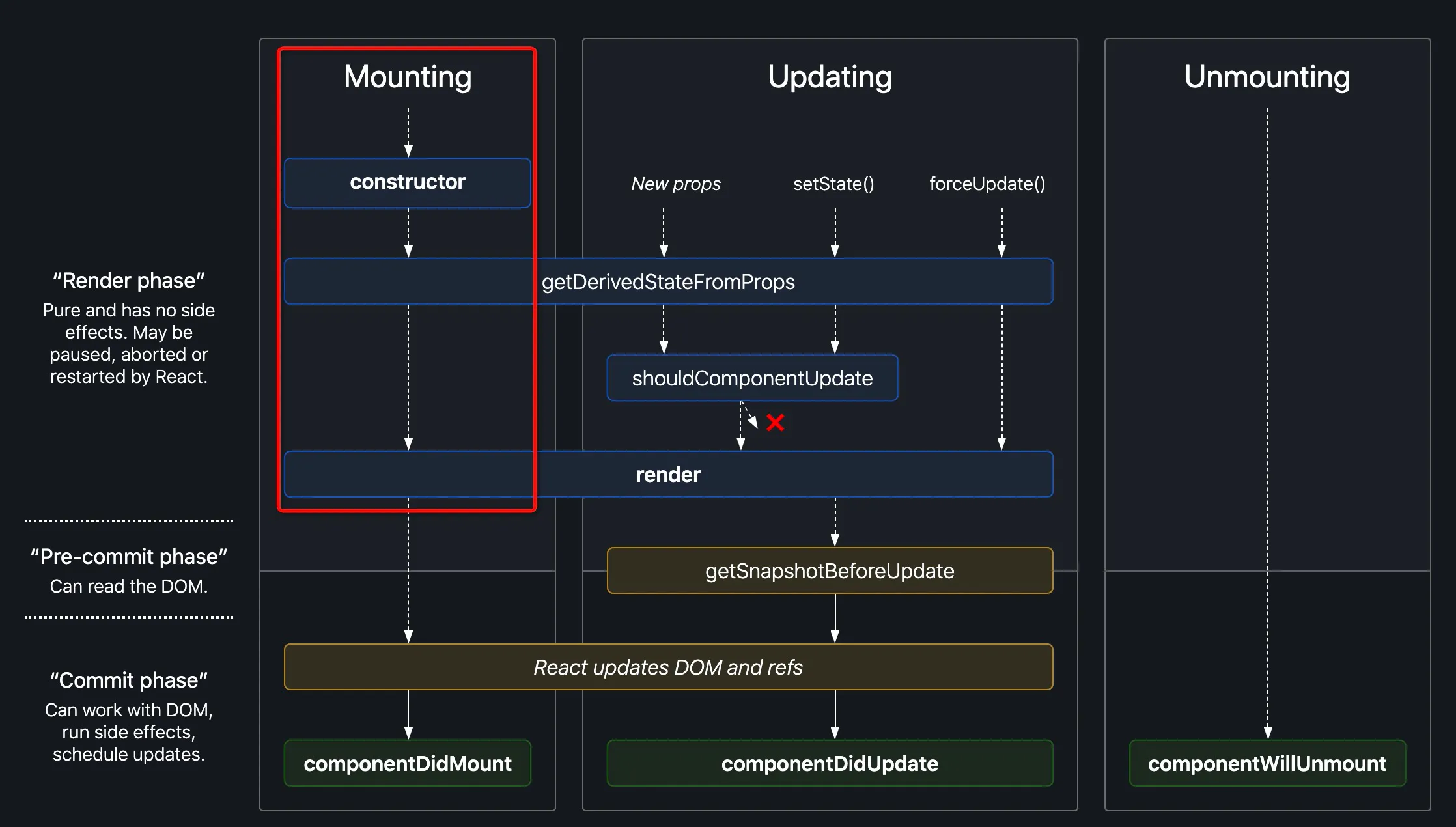
SSR组件渲染所用到的只有前三个生命周期
因此应该避免在顶层作用域中使用会产生副作用且需要被清理的代码,举个例子,如setInterval后在unMount周期清除,但由于永远不会执行到这个周期,因此计时器会一直存在
为了避免这种情况,请将含有、产生或依赖副作用的代码放在mounted生命周期,即useEffect Hook中
访问平台特有 API
通用代码不能访问平台特有的 API,如果你的代码直接使用了浏览器特有的全局变量,比如 window 或 document,他们会在 Node.js 运行时报错,反过来也一样。
对于浏览器特有的 API,通常的方法是在仅客户端特有的生命周期钩子中惰性地访问它们,如包裹在useEffect() 中
前后端路由
一般来说,前后端的路由系统是不同的,前端往往是基于拦截URL请求直接加载对应组件,而后端则是传统地基于路径进行寻址。
从某种意义上说,这也和平台特有API相关,如react-router其实依赖于浏览器提供的History API,但这在Node中显然不提供。
实现简单的SSR框架
众所周知,理解一个事物的最好方式就是亲自实践它,我们将从零开始,使用webpack和express搭建一个最最基础的React-SSR框架。这个框架要实现以下基本功能:
- 支持渲染React或Vue这样的现代框架SFC,一次编写,双端运行
- 以通用的方式管理前后端路由,正确地渲染和返回请求的组件(HTML)和资源链接(CSR加载脚本等)
项目初始化
建议直接Clone仓库,不用手动搭建脚手架:https://github.com/KiritoKing/ssr-demo
由于浏览器不能直接执行React JSX代码,因此我们需要像传统的CSR项目一样先搭建脚手架。(上面这些代码都是不能直接跑的)
- 使用webpack解析引用依赖,并使用babel转译React JSX代码为JS代码
- 使用express构建后端服务
推荐直接Clone仓库:
git clone https://github.com/KiritoKing/ssr-demo.git
cd ssr-demo
pnpm i
pnpm dev # build and run server on localhost:3001如果一切顺利,可以直接访问到localhost:3001上的计数器应用了。

理解架构
就这个项目,我们来理解一下这个最简单的SSR应用是如何工作的,整个项目的目录结构如下:
├── src
│ ├── client
│ │ ├── index.js // 客户端业务入口文件
│ ├── server
│ │ └── index.js // 服务端业务入口文件
│ ├── components // React 组件
│ │ └── App.js
│ │
├── config // 配置文件夹
│ ├── webpack.client.js // 客户端配置文件
│ ├── webpack.server.js // 服务端配置文件
│ ├── webpack.common.js // 共有配置文件
├── .babelrc // babel 配置文件
├── package.json首先我们看webpack配置~/config/webpack.*.js(仅展示关键代码),这有助于我们理解整个项目是如何运行的
// common:在打包时使用babel转译
{
test: /\.js$/,
exclude: /node_modules/,
loader: "babel-loader",
}
// client: 指定客户端加载SPA的入口,也就是水合脚本,打包到/public/index.js,供浏览器请求初始化组件
{
entry: "./src/client/index.js",
output: {
filename: "index.js",
path: path.resolve(__dirname, "../public"),
}
}
// server: 指定服务器入口,打包到/build/bundle.js中,用于启动服务器
{
target: "node", // 为了不把nodejs内置模块打包进输出文件中,例如:fs net模块等;
mode: "development",
entry: "./src/server/index.js",
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "../build"),
},
externals: [nodeExternals()], // 为了不把node_modules目录下的第三方模块打包进输出文件中,因为nodejs默认会去node_modules目录下去寻找和使用第三方模块。
}可以看到,整个编译流程分为了client和server两部分,在浏览器端和服务器端分别执行不同的工作。接下来,我们再去看看client和server分别做了什么事。
// server/index.js
import express from "express";
import { renderToString } from "react-dom/server";
import React from "react";
import App from "../components/App";
const app = express();
app.use(express.static("public")); // 重要:让前端能够请求到SPA Hydrate脚本
const content = renderToString(<App />); // 渲染组件
console.log(content);
app.get("*", function (req, res) {
// 嵌入HTML模板中(注意<script>标签)
res.send(`
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>React SSR</title>
</head>
<body>
<div id="root">${content}</div>
<script src="/index.js"></script>
</body>
</html>
`);
});
app.listen(3001);
console.log("Listening 3001");上面是服务端的基本工作流程:开放服务器(包括资源)→接收请求→根据URL渲染组件→生成HTML返回给浏览器。
我们可以试着删除<script> 标签,我们可以看到页面立刻失去了响应性。
// client/index.jsimport React from "react";import App from "../components/App";import { hydrateRoot } from "react-dom/client";hydrateRoot(document.getElementById("root"), <App />);相比服务端,客户端做的事明显就少了很多,仅仅是对组件进行了水合。
- 这里的工作其实和传统CSR里的
index.js很像,只是从render变成了hydrate - 可以注意到,在服务端和浏览器都对同一组件
<App>进行了渲染,只是具体工作内容不同
⭐所谓同构渲染的过程就是编写一份组件,分别在服务端和客户端执行一次,合起来加载出完整应用
完善更多功能
上面这个例子只能实现非常基础的页面,如服务端资源获取等都还不能实现,我们还需要为它添加更多功能才能让它看起来真正可用。
通用路由
路由部分代码:Branch - feat_router
我们先引入经典的SPA路由:react-router,虽然react-router推荐我们使用remix来实现SSR相关功能,但我们还是直面裸露的核心。
# Official installation command for react-router 6
pnpm add react-router-dom localforage match-sorter sort-by和SPA一样,我们先修改React组件部分结构,制作一个简单的多页面应用:
// Greeting.js
const Greeting = () => {
return (
<div>
<p>Hello!</p>
<Link to="/counter">To Counter</Link>
</div>
);
};
// Counter.js
// 将原App.js迁移过来
// Routes.js
import React from "react";
import { Route } from "react-router-dom";
import Greeting from "./Greeting";
import Counter from "./Counter";
import { Routes } from "react-router-dom";
const AppRouter = () => (
<Routes>
<Route path="/" element={<Greeting />}></Route>
<Route path="/counter" element={<Counter />}></Route>
</Routes>
);
export { AppRouter };
// App.js
const App = () => {
return (
<BrowserRouter>
<AppRouter />
</BrowserRouter>
);
};注意这里我们单独声明了一个Routes组件,因为除了客户端(<App />)外服务端也会用到它。
接下来修改服务端,我们修改content的内容为<StaticRouter>,这是服务端专用的Router,其中location参数用于根据URL寻找并加载组件:
// server/index.js
import { StaticRouter } from "react-router-dom/server";
// ...其他代码已省略,详见仓库
const content = renderToString(
<StaticRouter location={req.path}>
<AppRouter />
</StaticRouter>
);由于我们为服务端响应添加了log打印,我们可以发现服务端只渲染了第一次请求的页面(首屏渲染),后续都加载都是在客户端完成的,这符合我们的预期。(页面路由跳转后台并没有新的日志产生)
⭐一种意外的情况是在SPA未加载完全的情况下点击跳转路由,由于事件绑定还未完成,前端路由不能拦截请求,这种情况仍会向后端发送请求。
全局状态管理
redux部分代码:Branch - feat_redux
我们这里使用经典的redux进行全局状态管理。先引入redux-toolkit,使用RTK将优化我们创建redux应用的过程,避开冗余的模板代码(如action常量、reducer生成等)编写。
pnpm add @reduxjs/redux-toolkit react-redux我们将<Counter> 组件里的状态提升到redux中。
首先我们创建src/store目录,初始化store,这部分和一般的redux开发没有区别:
// store/slices/counter.js
import { createSlice } from "@reduxjs/toolkit";
export const counterSlice = createSlice({
name: "counter",
initialState: {
value: 0,
},
reducers: {
increment: (state) => {state.value += 1},
decrement: (state) => {state.value -= 1},
setValue: (state, action) => {
state.value = action.payload
},
},
});
export const { increment, decrement, setValue } = counterSlice.actions;
export default counterSlice.reducer;
// store/index.js
import { configureStore } from "@reduxjs/toolkit";
import counterReducer from "./slices/Counter";
export const store = configureStore({
reducer: {
counter: counterReducer,
},
});接下来我们为组件添加<Provider>,在服务端和客户端都要添加(仅展示改动代码,完整请见仓库):
// server/index.js
// ...
const content = renderToString(
<Provider store={store}>
<StaticRouter location={req.path}>
<AppRouter />
</StaticRouter>
</Provider>,
);
// components/App.js
const App = () => {
return (
<Provider store={store}>
<BrowserRouter>
<AppRouter />
</BrowserRouter>
</Provider>
);
};
// components/Counter.js
const Counter = () => {
const count = useSelector((state) => state.counter.value);
const dispatch = useDispatch();
return (
<div>
<div>You click {count} times</div>
<button onClick={() => dispatch(increment())}>Click Me!</button>
<Link to="/">Back</Link>
</div>
);
};最终运行效果如下:
数据预取
数据预取相关代码:Branch - feat_thunk
一般较复杂的页面都需要从后台API获取数据来呈现,在SSR同构渲染中我们有两种实现方案:
- 在浏览器组件生命周期的
mount中发起异步请求,具体来说就是useEffect包裹 - 在服务器渲染时就请求数据并注入到返回的HTML中
在实际生产中我们一般选择后者,因为生产环境中前端服务和后端API一般都部署在同一机房内,网络请求更快也更稳定,因此服务器可以有效提高加载体验。
⭐实现步骤:实现**Thunk****请求 → 实现****getInitialProps**服务端加载 → 服务端数据注水
为了模拟这个场景,我们创建一个新的Slice用于存储模拟的用户列表,并创建一个页面用于显示用户列表。
我们先用thunk实现一个基本的异步请求,这里使用RTK提供的封装。根据RTK官方指导,我们**使用createAsyncThunk**直接创建一个thunk请求。
接收两个参数,返回
Thunk对象,它也是一个标准的action creator,在dispatch后得到一个Promise第一个参数是
type,一般是<slice>/<action>的格式,它会根据Promise状态自动生成三个action type,就像这样<slice>/<action>/<state>pendingfufilledrejected
- 第二个参数是一个异步函数,在这里进行异步请求,它的返回值将作为
action.payload
createAsyncThunk并不会创建reducer,它只会返回一个action creator,因此我们需要在extraReducers中手动构建,具体代码如下所示- 使用thunk时和普通action无异,直接dispatch即可
// store/slices/contacts.js
import { createAsyncThunk, createSlice } from "@reduxjs/toolkit";
export const getUserList = createAsyncThunk(
"contacts/getUserList",
async () => {
const resp = await fetch("https://reqres.in/api/users"); // 直接使用reqres.in提供的API
const data = await resp.json();
console.log(data);
return data.data;
}
);
export const contactsSlice = createSlice({
name: "contacts",
initialState: {
userList: [],
loading: true,
},
reducers: {
setList: (state, action) => {
state.userList = action.payload;
},
addUser: (state, action) => {
state.userList.push(action.payload);
},
removeUser: (state, action) => {
state.userList.splice(state.userList.indexOf(action.payload), 1);
},
},
extraReducers: (builder) => {
builder.addCase(getUserList.fulfilled, (state, action) => {
state.userList = action.payload;
state.loading = false;
});
},
});
export const { setList, addUser, removeUser } = contactsSlice.actions;
export default contactsSlice.reducer;
// 记得在store/index.js中也添加这个Slice接着我们创建一个页面用于显示获取到的数据,注意在Routes中也要添加这个页面:
// components/Contacts.js
import React, { useEffect } from "react";
import { useDispatch, useSelector } from "react-redux";
import { getUserList } from "../store/slices/contacts";
import { Link } from "react-router-dom";
const ContactItem = (props) => {
const { avatar, first_name, last_name, email, id } = props;
return (
<div
style={{
display: "flex",
flexDirection: "row",
alignItems: "center",
marginBottom: "5px",
}}
>
<img
src={avatar}
alt="avatar"
style={{
width: "30px",
height: "30px",
borderRadius: "50%",
marginRight: "5px",
}}
/>
<div>
<div>Name: {`${first_name} ${last_name}`}</div>
<div>Email: {email}</div>
<div>ID: {id}</div>
</div>
</div>
);
};
const Contacts = () => {
const users = useSelector((state) => state.contacts.userList);
const dispatch = useDispatch();
useEffect(() => {
const init = async () => {
const res = await dispatch(getUserList()).unwrap();
console.log(res);
};
init();
}, []);
return (
<div>
<div>
<Link to="/">Back</Link>
</div>
<ul>
{users.map((user) => (
<li>
<ContactItem {...user} />
</li>
))}
</ul>
</div>
);
};
export default Contacts;
运行应用,我们可以看到这样的页面,可以看到thunk请求正常处理了。
但这样仅仅是在客户端请求了数据,服务端仍是一片空白,因为useEffect的生命周期并不会在服务端渲染时运行,我们需要自己“定义“一个能在SSR时运行的生命周期。
在NextJS中,getInitialProps用于在服务端请求数据,这里我们也实现一份自己的getInitialProps。

由于我们的应用是SPA,因此实际是由路由react-router决定渲染哪个组件的,因此实际加载顺序是req→router→component,因此我们找到了需要的生命周期——只需要在Router选择时就执行数据获取即可。
恰巧,react-router 6 提供了新的Data API,提供了**loader**函数来在组件渲染前加载数据。
为了启用新的Data API,我们需要修改以前的写法,用routes数组而不是<Route> 组件来定义路由,并在服务端和客户端分别用create* 语法来创建路由。
// src/routes.js
const routes = [
{
path: "/",
Component() {
return <Greeting />;
},
},
{
path: "counter",
Component() {
return <Counter />;
},
},
{
path: "contacts",
async loader() {
const dispatch = store.dispatch;
const data = await dispatch(getUserList());
console.log(data);
return data.payload;
},
Component() {
const loaderData = useLoaderData();
console.log(loaderData);
return <Contacts />;
},
},
];可以看到,我们用Component()函数定义组件,其内就是一个普通的函数组件;而loader则是一个在组件实际渲染之前被调用的普通函数,在服务端和客户端加载时都会被调用,也就是说loader也会随着前后端路由分别被运行两次。
- 服务端:在请求URL时触发,由
StaticRouter调用,在组件渲染之前执行,一般用于加载数据(到store或Hook)以便HTML带有正确数据 - 客户端:当SPA应用加载完毕后,整个应用就走前端路由,不再因为URL变化而请求后端;而
loader在客户端就是在前端路由加载完毕或切换时会触发,用于提前获取数据 在SSR中服务端和客户端的
loader相互配合,提高了首屏加载速度和页面切换速度(在SPA加载完成前先让用户看到HTML预渲染内容顶着)- SPA加载脚本往往很大,HTML则相对较小,相较于JS可以更快加载和显示,在JS加载完成之前HTML可以先呈现给用户
- 需要注意预加载的数据要通过 “注水”的形式让前端可以正确获取一致的初始值,否则数据不一致会导致前端
hydrate会失败,放弃预渲染的HTML回到纯CSR上
这下思路就清晰了,我们只需要**在loader**中dispatch thunk action就可以完成数据的异步加载,而这个返回值可以在组件中用useLoaderData() Hook来调用(这里仅仅将它看作普通的生命周期函数,并没有用到返回值),最终代码如上面所示。
然后我们再分别对客户端和服务端的路由做适配,让它们兼容Data API。这里需要注意的是服务端,根据react-router的要求,我们需要先将express请求转换成fetch请求。
// components/App.js - 客户端路由修改
const router = createBrowserRouter(routes);
const App = () => {
return <RouterProvider router={router}></RouterProvider>;
};
// server/index.js - 服务端路由修改
import createFetchRequest from "./request";
import { createRequestHandler } from "@remix-run/express"; // 需要安装这个包,且这个引用不能删除
const handler = createStaticHandler(routes);
app.get("*", async function (req, res) {
const fetchRequest = createFetchRequest(req); // 将express请求转化成fetch 供staticHandler.query调用
const context = await handler.query(fetchRequest);
const router = createStaticRouter(handler.dataRoutes, context);
const content = renderToString(
<Provider store={store}>
<StaticRouterProvider router={router} context={context} />
</Provider>
);
// ...
// server/request.js - react-router官方给的代码,用于将express请求转化成fetch
export default function createFetchRequest(req) {
let origin = `${req.protocol}://${req.get("host")}`;
// Note: This had to take originalUrl into account for presumably vite's proxying
let url = new URL(req.originalUrl || req.url, origin);
let controller = new AbortController();
req.on("close", () => controller.abort());
let headers = new Headers();
for (let [key, values] of Object.entries(req.headers)) {
if (values) {
if (Array.isArray(values)) {
for (let value of values) {
headers.append(key, value);
}
} else {
headers.set(key, values);
}
}
}
let init = {
method: req.method,
headers,
signal: controller.signal,
};
if (req.method !== "GET" && req.method !== "HEAD") {
init.body = req.body;
}
return new Request(url.href, init);
}
完成了上述定义后我们应该已经可以在服务端生成带有数据的HTML了,如下图所示:
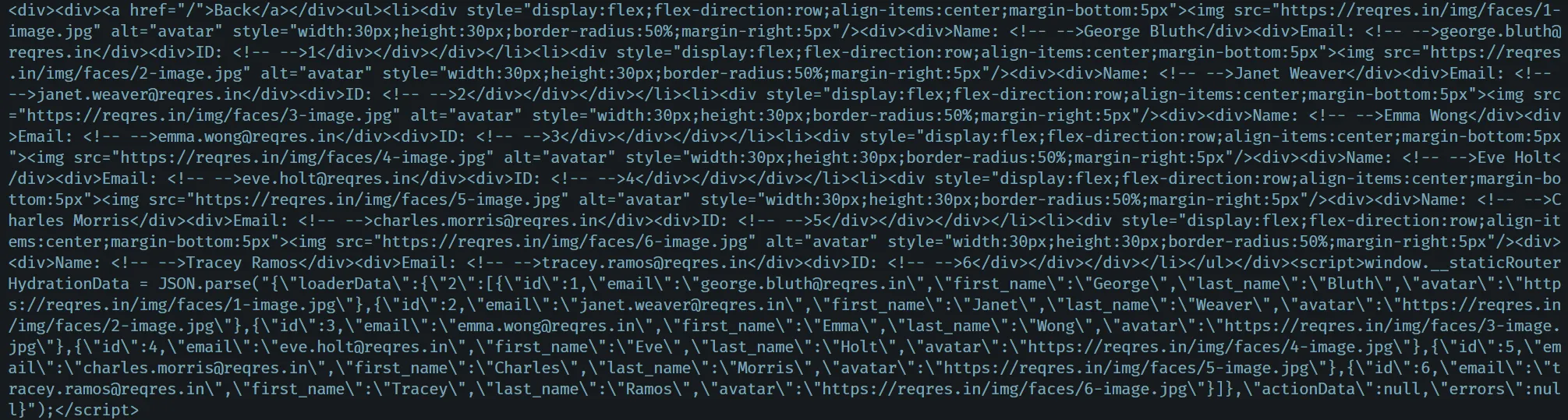
日志中可看到带有内容的HTML(可能略有区别)
既然完成了服务端数据获取,我们理应可以在Contacts.js中的Effect中删除init()调用,完全禁止客户端获取数据,我们会开心地发现网页一闪而过又成了白屏。
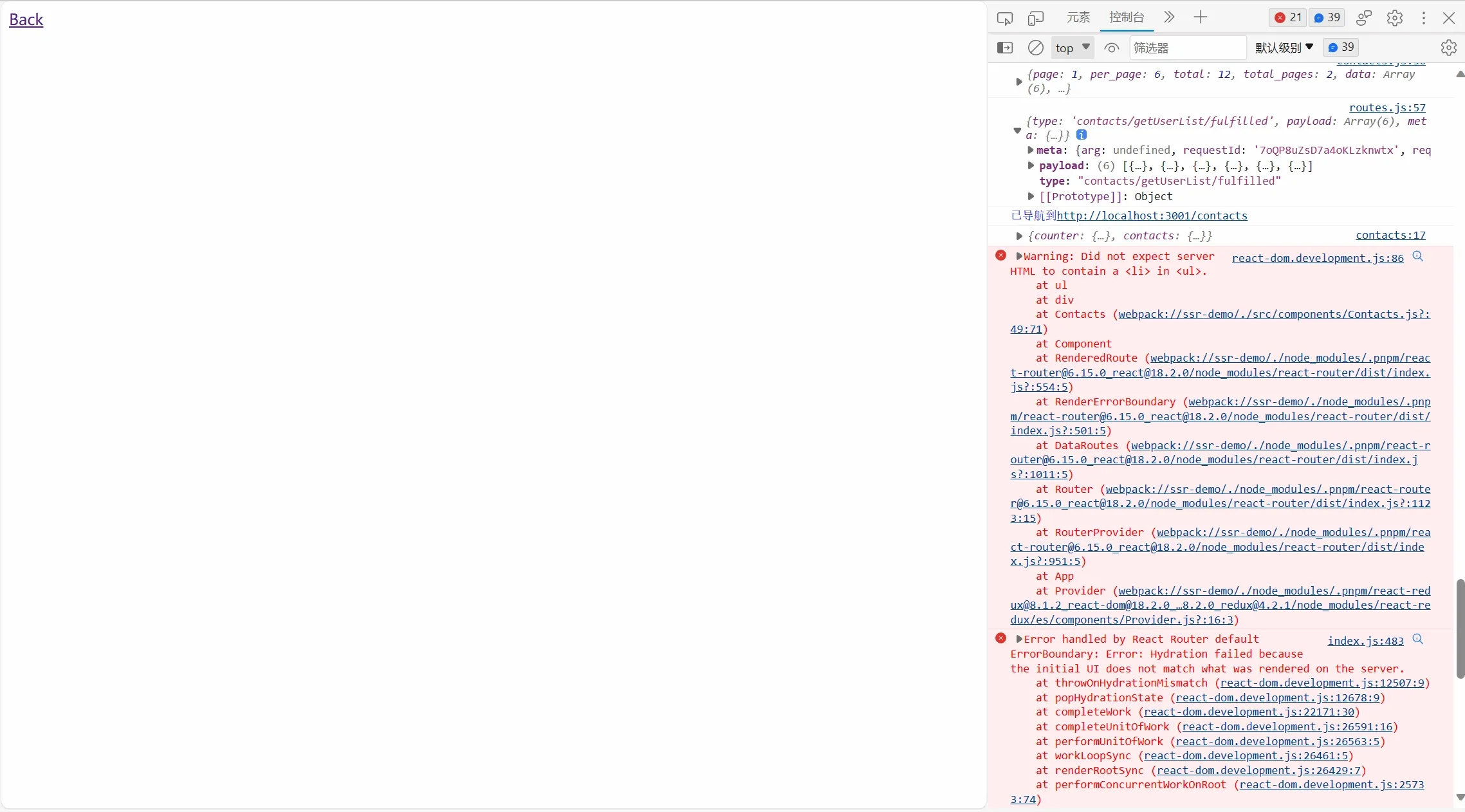
尝试阅读右边的错误信息,我们发现这是因为状态不一致导致的hydrate失败,应用回落到了CSR模式。
仔细一想,我们只修改了服务端的Store,没有管客户端的Store。客户端Store的初始值仍是空的,它渲染出的DOM自然和服务端传来的不同,CSR就采用了客户端渲染出的HTML替代了服务端的HTML,而useEffect中又删除了获取数据相关代码,自然就一片空白了。
因此,我们要给客户端的Store也赋上初值。为了让每个页面都独立地更新,我们采用将store附到window全局变量下的方式,这种方式又叫 “数据注水”。
⭐“数据注水”和前面提到的“水合(hydrate)”并非同一概念。前者是在服务端将预获取到的数据注入到全局变量中以供客户端初始化,保持数据一致;后者是客户端在已经渲染好的DOM树上进行React渲染,以还原应用响应性的操作。
我们先修改服务端server/index.js中的模板HTML代码,主要看增加的<script>标签:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta
name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"
/>
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>React SSR</title>
</head>
<body>
<div id="root">${content}</div>
<script>
const INIT_STATE = ${JSON.stringify(store.getState())}
console.log(INIT_STATE)
window.INITIAL_STATE = INIT_STATE;
</script>
<script src="/index.js"></script>
</body>
</html>在服务端完成注入后,我们要在客户端添加对应的初始化代码。
// client/store.js: 创建专用于客户端的store
import { configureStore } from "@reduxjs/toolkit";
import counterReducer from "../store/slices/counter";
import contactsReducer from "../store/slices/contacts";
export const clientStore = configureStore({
reducer: {
counter: counterReducer,
contacts: contactsReducer,
},
preloadedState: window.INITIAL_STATE, // 必须独立声明的原因是Node环境没有window
devTools: true,
});
// client/index.js
import React from "react";
import App from "../components/App";
import { hydrateRoot } from "react-dom/client";
import { Provider } from "react-redux";
import { clientStore } from "./store";
// 这里将Provider提到了index.js是因为App是服务端也会调用的通用组件,调用window就会报错
hydrateRoot(
document.getElementById("root"),
<Provider store={clientStore}>
<App />
</Provider>
);现在就应该能正常运行应用了,如果遇到任何问题欢迎来仓库提Issue。
效果验证
我们开启低速模拟,来检验SSR对首屏加载速度的作用,以下测试均已关闭缓存,慢速3G模拟环境。
修改网络配置
在已经加载好的SPA中进行前端路由切换:
CSR加载(前端路由切换)
开启SSR后首屏进入 /contacts:(直到录制结束JS都没加载出来)
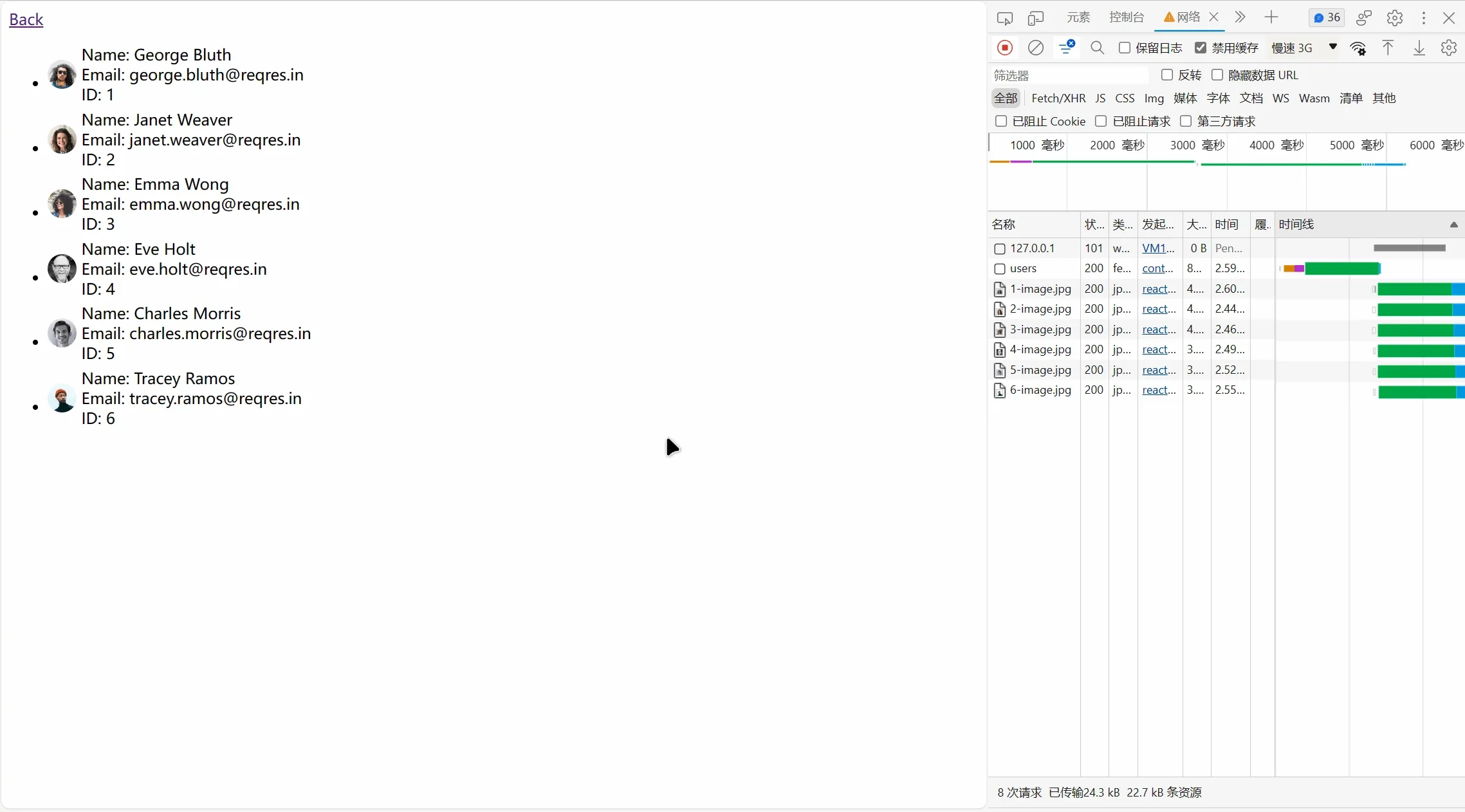
⭐因此我们可以看出,在网络不佳的情况下,SSR是加载速度优化的重要手段,毕竟现在动辄几兆乃至几十兆的JS文件,在极端情况下可能造成长达数十秒的白屏时间,而SSR就可以通过体积较小的HTML来优化用户体验,让用户先看到一部分结果。