

本篇文章着重于讨论 JavaScript 语言一些原始的特性(颇有”祖宗之法不可变“的意味的一些语言设计),不过分地关注其实现细节和设计初衷。
注意,这里只讨论 JavaScript 语言本身的特性,而不关心具体实现上的差别(如 V8 引擎的具体实现或 Node 环境与浏览器环境的 API 差别)。
其他面试相关文章
- webpack和其他打包工具(esbuild, bun, vite, turbopack)
- 现代状态管理
- 浏览器缓存与网络(http2.0和https)
- react-fiber机制
- state刷新机制
- git原理和ci-cd部署
- vue2&3和react16+&18的区别
基本数据类型
JS 中有8种(ES6)基础数据类型,包括:
7种基础数据类型(存储在栈中):
number,string,boolean,undefined,null,BigInt,Symbol其中
BigInt和Symbol是ES6引入的新类型BigInt用于存储number的双精度浮点数无法存储的大整数Symbol用于存储独一无二、不会改变的值,每个值都有一个唯一的指针(就算是两个一样的字面量),主要是为了解决可能出现的全局变量冲突的问题
1种引用类型(存储在堆中,实际上是指针):
objectobject有许多衍生类型,如Array,Map,Set等,他们的原型都是Object->Function
null 和 undefined
null 和 undefined 是特殊的基本类型,它们没有任何拓展方法。
null相当于一个卷纸盒里没有卷纸的情况,至少这里还有一个卷纸盒(声明了一个变量,且赋予了null初值)undefined相当于连卷纸盒都没有的情况(声明了变量,但并没有初始化)
除此之外,还有一种情况是 undeclared,它并不是一种数据类型,它代表着已经存在于作用域种但没有初始化的变量,常见于局部死区。
原型与原型链继承
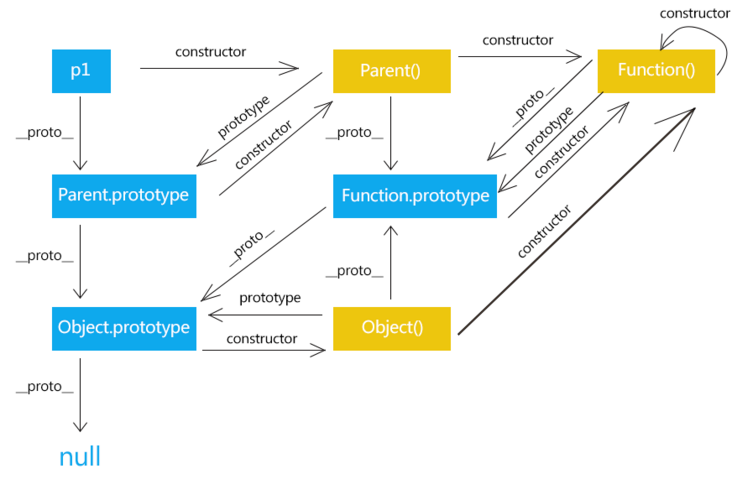
JavaScript 是基于原型的而不是基于类的,面向对象用原型链实现继承而不是类的派生。
基本概念
JavaScript 对象是动态的属性“包”(指其自己的属性),对象又分为普通对象和函数对象两种。
- 每个对象都有
__proto__属性,它指向这个对象的原型对象(prototype) 只有函数对象有
prototype(原型对象)属性,它有默认拥有两个属性:constructor和__proto__(默认表示在log时不会显示出来)constructor属性用于记录实例是由哪个构造函数创建,函数对象的prototype的constructor默认是它自己,普通对象则是它的构造函数。__proto__属性指向对象的父类(对象)的原型对象(prototype),直到Object的prototype属性为null,原型链结束.construtor代表自身(子类自己),__proto__代表父类(原型链)
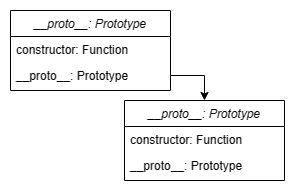
- 任何函数都可以作为构造函数,但是并不能将任意函数叫做构造函数,只有当一个函数通过
new关键字调用的时候才可以成为构造函数。 - 当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索,直到找到一个名字匹配的属性或到达原型链的末尾。
- 需要注意的是,当继承的函数被调用时,this 指向的是当前继承的对象,而不是继承的函数所在的原型对象。
- 要检查对象是否具有自己定义的属性(即这个属性在
this里而不是__proto__中),而不是其原型链上的某个属性,则必须使用所有对象从Object.prototype继承的hasOwnProperty方法。
在原型链上查找属性比较耗时,对性能有副作用,这在性能要求苛刻的情况下很重要。另外,试图访问不存在的属性时会遍历整个原型链。
Fun Facts
以下事实均可以在浏览器环境或Node环境中验证。
- 由于 JS 会递归地查询原型链上的属性,因此在对象中可以直接访问直接父类的
constructor属性,其他顶层的未被遮蔽的父类属性也可以被直接访问,但修改会直接赋值到this中,并掩蔽prototype中的属性 - 如果你使用普通对象作为
prototype赋值给__proto__时,它寻找constructor时会调用它的__proto__.constructor,实际上就是Object(因为普通对象的__proto__属性就是Object.prototype)。 - 修改构造函数的
prototype和修改实例的__proto__在行为上是等价的(因为**同一构造函数的所有实例的****__proto__*都指向同一个对象,即构造函数的prototype) - 由于原型对象中
constructor代表自身,__proto__代表父类,因此任何构造函数(或者说任何函数)的constructor是Function(),__proto__则指向Object.prototype(MHY面试题)
JavaScript 如何实现继承
明白了原型(__proto__ 和 prototype)的概念和原型链的原理后,我们应该如何编写代码来实现继承呢?
直接继承
- 使用
Object.create(obj)创建对象,允许你指定一个将被用作新对象原型的对象,即将obj赋值给__proto__ 使用构造函数,通过
new关键字指定对象的__proto__属性为对应函数的prototype属性new首先会创建一个新的空对象- 它将新生成的对象的
__proto__属性赋值为构造函数的prototype属性,使得通过构造函数创建的所有对象可以共享相同的原型 - 使用
constructor.apply(obj, args)运行构造函数,并使其绑定到创建的对象中
- 直接修改
__proto__属性或者使用Object.setPrototypeOf(obj, prototype) - 也可以直接给
__proto__或者prototype属性赋值来增加原型上的属性
注意:原生原型不应该被扩展,除非它是为了与新的 JavaScript 特性兼容。
继承链
上面这些方法都只能执行一层的继承,如果我想像其他OOP语言一样拥有很长的继承链要怎么办呢?
最好的办法是使用ES6+提供的 class 语法糖,这里仅作为原型链的训练使用。
比如说我们有三个类,继承关系是:PrimaryStudent->Student->Person。
首先想到的方法如下:
function Person(name, age, gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
function Student(name, age, gender, score) {
Person.call(this, name, age, gender);
this.score = score;
}
function PrimaryStudent(grade, ...props) {
Student.apply(this, props);
this.grade = grade;
}
var xiaoming = new PrimaryStudent(2, '小明', 9, '男', 92);
console.log(xiaoming);但我们需要注意一点:调用了**Student构造函数不等于继承了Student**,而只是在 PrimaryStudent 中运行构造函数添加了对应的属性。
现在创建的对象的原型链是:this -> PrimaryStudent.prototype -> Object.prototype -> null。
而我们想要的原型链是:this -> PrimaryStudent.prototype -> Student.prototype -> Person.prototype -> Object.prototype -> null。
是的,想必你也想到了,我们可以直接修改 prototype 属性来得到正确的原型链,只是我们必须借助中间对象来实现正确的原型链。
我们将这个过程包装在一个函数中,函数中定义了一个空壳函数F来作为原型链的中间一环(F的constructor是子类的构造函数,而__proto__指向父类的原型):
function inherits(Child, Parent) {
var F = function() {};
F.prototype = Parent.prototype;
Child.prototype = new F();
Child.prototype.constructor = Child;
}这样就可以用下面的代码还原正确的原型链:
inherits(Student, Person);
inherits(PrimaryStudent, Student);
// PrimaryStudent -> Student -> Person -> Objectthis 指针
this 是 JS 的关键字之一,是 object 类型自动生成的一个内部对象,只能在内部使用,虽然大体上指的是本身及其所处环境,但根据调用的位置不同实际指向的地方是不同的。
众所周知 function 也是一个特殊的对象,而 this 其实也主要用于函数内部。
绑定规则
在看下面这些例子的时候很难不想到上面原型链中的this指向哪里,等看完了自然就有了答案。
默认绑定
function doSomething() {
this.a = 20
console.log(this.a)
}
a = 10
console.log(a) // 10
doSomething() // 20
console.log(a) // 20若函数调用的位置直接位于顶级作用域,就像“光杆司令”,就只能执行默认绑定,绑定到全局环境中(在浏览器中是window,Node环境中则是global,严格模式中则是undefined)
隐式绑定
function doSomething() {
console.log(this.a)
}
var obj = {
a: 2,
doSomething: doSomething
}
a = 10
doSomething() // 10
obj.doSomething() // 2函数调用的位置在对象内部时,函数就有了上下文对象,此时 this 就指向了上下文对象。需要注意的是,这里的上下文指的是直接上下文。
我们回忆使用 new 创建实例的原理,实际上也是 new 内部新建了对象,并把这个对象作为上下文对象调用构造函数,也就是说构造函数中的 this 指向我们创建的对象。
需要注意的,this**** 指向的上下文和词法作用域产生的闭包是两个不同的概念。
显式绑定
显式绑定可以通过一些方法强制给函数设置 this 指向的对象,这些方法定义在 Function 这个构造函数的原型中。
Function.call(this, thisArg, ...args)- 定义在原型中的函数的
this参数会在实例调用该方法时自动填入,和 Python 中的self很像 thisArg用于指定函数的this指针...args为变长参数列表
- 定义在原型中的函数的
Function.applay(this, thisArg, argArray)- 与
call的区别是参数列表是数组形式
- 与
Function.bind(this, thisArg, ...args)- 与
call的区别是它会返回一个函数以供调用,而不是直接执行
- 与
箭头函数(Lambda 表达式)
ES6中引入的 => 函数不受上述规则影响,而是完全由外部环境决定 this 的指向,且不能被手动修改(即对箭头函数使用call、bind 和 apply 是无效的)。但是它的外部环境(父作用域)仍受制于上述的 this 规则。
简单地说:箭头函数没有自己的 this,内部的 this 完全等价于外层的 this,通过查找作用域链来确定 this 的值。
const obj = {
a: 1,
say1: function () {
console.log(this.a);
},
say2: () => {
console.log(this.a);
},
say3: function () {
return () => {
console.log(this.a);
}
}
}
ext = obj.say1;
a = 2;
obj.say1(); // 1
obj.say2(); // undefined, this={}
obj.say3()(); // 1
ext(); // 2闭包与作用域
词法作用域(Lexical Context)就是定义在词法分析阶段的作用域。
这个叙述可能不是很清晰,我们换一个说法:词法作用域又称静态作用域,与之相对的是动态作用域。静态作用域在程序编译(词法分析)阶段,变量的作用域就已经按照代码层级确定了;而动态作用域会在代码执行阶段动态地从调用栈的作用域中搜索变量。
举个例子:
var value = 1;
function foo() {
console.log(value);
}
function bar() {
var value = 2;
foo();
}
bar();
// 结果是 1上述例子很清晰地说明了 JS 是静态作用域(词法作用域)语言,即函数的作用域在函数定义的时候就决定了,查找时根据书写的位置,查找上面一层的代码,也就是 value 等于 1,所以结果会打印 1。(否则的话会按照调用栈查 bar 中的变量,打印 2)。
词法作用域给 JS 带来了以下规则:
- 函数可以访问当前函数作用域外部的变量
- 整个代码结构中只有函数可以限定作用域(也就是说在ES6以前的JS中一个文件内只存在**全局作用域(Global Scope)和函数作用域(Function Scope)**两种作用域,其中函数作用域可以嵌套、重复地存在)
- 作用规则首先使用提升规则分析(即变量提升现象)
- 如果当前作用域中有了名字了,就不考虑外面的名字
知道了词法作用域的基本概念后,我们来看看词法作用域在 JS 中具体体现在了哪些地方吧。
闭包(closure)
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是在支持头等函数的编程语言中实现词法绑定的一种技术。
闭包在实现上是一个结构体,它存储了一个函数(通常是其入口地址)和一个关联的环境(相当于一个符号查找表)。环境里是若干对符号和值的对应关系,它既要包括约束变量(该函数内部绑定的符号),也要包括自由变量(在函数外部定义但在函数内被引用),有些函数也可能没有自由变量。闭包跟函数最大的不同在于,当捕捉闭包的时候,它的自由变量会在捕捉时被确定,这样即便脱离了捕捉时的上下文,它也能照常运行。
最开始闭包被广泛地用于函数式编程语言如 LISP,后来很多命令式编程语言也逐渐开始支持闭包(如臭名昭著的 Javascript)
闭包对于初学者难以理解的地方其实仅仅在于这个著名的”翻译谬误“,将 closure 这个还算形象的名称翻译成了 ”闭包" 这个相对晦涩的汉语名称。闭包实际上就是用来指代某些其开放绑定(自由变量)已经由其语法环境完成闭合(或者绑定)的lambda表达式,从而形成了闭合的表达式,就像关上了访问其中元素的大门一样。
简而言之,闭包让开发者可以从内部函数访问外部函数的作用域。在 JavaScript 中由于词法作用域的存在,闭包会随着函数的创建而被同时创建。
举个例子:
function makeFunc() {
var name = "Mozilla";
function displayName() {
console.log(name);
}
return displayName;
}
var myFunc = makeFunc();
myFunc(); // Mozilla
闭包的实际作用
闭包允许将函数与其所操作的某些数据(环境)关联起来,这显然类似于面向对象编程。
在面向对象编程中,对象允许我们将某些数据(对象的属性)与一个或者多个方法相关联。因此,通常你使用只有一个方法的对象的地方,都可以使用闭包。
更抽象的说,闭包象征着一种封装思维,将某些属性和方法打包封装起来,可以隐藏细节和保护数据,这样来说如自定义 Hook 等都属于广义的闭包。
以下是一些闭包的用处:
- 模拟 OOP 中的私有成员和方法
- 隐藏变量,避免全局作用域污染
以下是实际应用场景:
- 模块化开发(以前没有模块作用域的时候用闭包封装模块的命名空间)
- 高阶函数、科里化、节流防抖等需要内部判断状态的函数
性能开销
总结:如果没有绑定作用域的特殊需求,请不要使用闭包!
如果不是某些特定任务需要使用闭包,在其他函数中创建函数是不明智的,因为闭包在处理速度和内存消耗方面对脚本性能具有负面影响。
例如,在创建新的对象或者类时,方法通常应该关联于对象的原型,而不是定义到对象的构造函数中。原因是这将导致每次构造器被调用时,方法都会被重新赋值一次(也就是说,对于每个对象的创建,方法都会被重新赋值)。
需要注意的是,使用原型定义也会引入额外的原型链查找开销,因此这其实是一种 trade-off,只是一般单层查找开销略低于反复构造的开销。
除此之外,闭包的滥用还会导致变量不会随着函数退栈被垃圾回收机制回收,可能导致内存泄漏问题。
比如下面的代码:
// 使用闭包定义公有方法:每次构造新对象都会重新赋值一次方法
function MyObjectClosure(name, message) {
this.name = name.toString();
this.message = message.toString();
this.getName = function() {
return this.name;
};
this.getMessage = function() {
return this.message;
};
}
// 使用原型继承定义公有方法:所有对象共用一个地址(但会带来原型链查找的开销)
function MyObject(name, message) {
this.name = name.toString();
this.message = message.toString();
}
MyObject.prototype.getName = function() {
return this.name;
};
MyObject.prototype.getMessage = function() {
return this.message;
};
变量提升和局部死区
在 JS 的执行过程(具体地说是函数运行栈帧的创建过程,这就涉及到 V8 引擎的实现了)中,所有标识符(包括函数和变量)的声明部分会被添加到名为Lexical Environment 的结构体(这实际上就是词法作用域的实际载体,也是作用域链的结点)中,这看起来就像是提升到当前作用域的最前面,所以这些变量和函数能在它们真正被声明之前使用。
而根据变量类型的不同,具体的提升行为也不同,但大体上都是只提升声明部分。
- 函数提升:因为函数本身就是一个指针,当JavaScript引擎遇到函数时,它会从词法环境中找到这个函数并执行它。
sayHi() // Hi there!
function sayHi() {
console.log('Hi there!')
}var变量提升:JavaScript在编译阶段会找到var关键字声明的变量会添加到词法环境中,并初始化一个值undefined(而不是用户定义的赋值初始化行为),在之后执行代码到赋值语句时,会把值赋值到这个变量
var name // 声明变量
name = 'John Doe' // 赋值操作let&const变量提升:只有使用var关键字声明的变量才会被初始化undefined值,而let和const声明的变量则不会被初始化值,因此在 JavaScript 引擎在声明变量之前,无法访问该变量。这就是我们所说的 Temporal Dead Zone(局部死区),即变量创建和初始化之间的时间跨度,它们无法访问。class提升:ES6中的新关键字,同样会被提升,但在实际声明前是不能调用的(这点与构造函数不同),也存在局部死区问题。
let peter = new Person('Peter', 25) // ReferenceError: Person is not defined
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
}
let john = new Person('John', 25);
console.log(john) // Person { name: 'John', age: 25 }
作用域链
根据规则2:只有函数才能制造作用域结构,那么只要是代码,至少有一个作用域,即全局作用域。
凡是代码中有函数,那么这个函数就构成另一个作用域。如果函数中还有函数,那么在这个作用域中就又可以诞生一个作用域,那么将这样的所有作用域列出来,可以有一个结构:函数内指向函数外的链式结构。
举个(相同的)例子:
function foo() {
console.log(a); // 2
}
function bar() {
var a = 3;
foo();
}
var a = 2;
bar();这段代码的作用域链如下图所示:
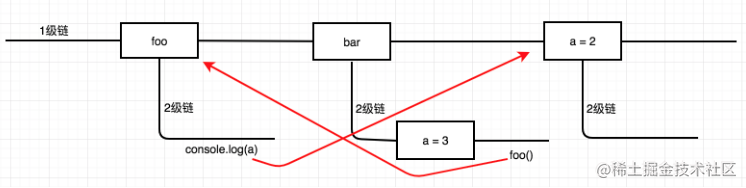
在搜索变量时,只会按照作用域链向上搜索,而词法作用域(静态作用域)又决定了其只与在代码中定义的地方有关,所以无论函数在哪里被调用,也无论它如何被调用,它的词法作用域都只由函数被声明时所处的位置决定。