
之前在腾讯文档前端面试的时候,考官问我经典八股之一的浏览器事件循环,编程题也是与之相关的。我直接被问瓜了,深感自己在JS基础这方面的知识薄弱,虽然以后可能不做前端了,但还是来恶补一下这方面的知识为好。
JS是如何运行的
为了理解事件循环,我们需要首先简要理解JS引擎的执行过程。
众所周知,Javascript是解释型的脚本语言,即运行环境在拿到它要运行的JS任务的时候得到的是一串文本,而不是编译好的二进制文件,这就要求JS解释器要立刻解析语法并生成二进制代码用于执行,以Chromium的V8引擎为例:
V8引擎模拟操作系统调用,分为两个核心部分:执行栈(execution stack)和堆(heap)
- 执行栈存放函数调用的栈帧(执行上下文,execution context)
- 堆则存放本地变量的值
函数在运行过程中分为创建阶段(creation phase)和执行阶段(execution phase)
- 创建阶段会把函数的执行上下文(execution context)压入执行栈顶,执行上下文包含了函数的参数、局部变量等信息
- 执行上下文入栈后将初始化执行上下文,包括VO(variables, functions and arguments)、**Scope Chain(VO Chain, 调用链)和
this*指针 - 上下文初始化完毕后开始执行,执行完毕后上下文将从栈顶弹出
上一个试图在浏览器中直接运行二进制的Flash坟头草已经三尺高了,而WebAssembly其实采取了一种折衷方案,相当于C->汇编->机器码中省去了汇编过程,但编译和链接的过程仍保留了下来

为什么需要事件循环(event loop)
要回答这个问题,我们要先从JS语言和它的解释器本身的特性谈起:
- 前提1:JS解释器(如V8)是单线程的
- 前提2:JS解释器在接收一段代码后会一口气从头到尾完整执行,中间不能暂停或释放所有权
- 前提3:执行JS代码的和构建页面DOM的(渲染线程)是两个东西,且解释器线程和渲染线程是相互阻塞(互斥的),这是由于JS引擎和渲染线程都可能读取和操作DOM,这导致二者处于竞争状态,所以为DOM这个临界资源上了一把互斥锁。
前提3也导致了NodeJS中的事件循环和浏览器中并不一样,理论上JS解释器标准由ECMA委员会制定(只对JS语言特性负责),而浏览器事件循环标准由HTML委员会制定,因此不同Host环境下事件循环可能是不一样的,且与JS解释器彼此独立。
从以上三个前提我们可以看出,由于JS解释器只会一根筋练死劲儿(一口气跑到底),还不管其他人的死活(渲染管线),这样的话JS执行过程中用户界面出现无响应的情况(如获取数据的过程中网页假死),也无法实现即时事件响应(如按下按钮调用函数),这对于响应式网页UI来说是致命的缺陷。
为了弥补这些缺陷,实现异步和响应的需求,我们就必须引入事件循环机制(event loop)。
如何实现并行(非阻塞调用)
为了实现我们的并行JS宏图,我们可以先参考操作系统中是如何实现并行多任务的。
回顾专业知识,我们可以总结现代计算机操作系统的异步实现为:宏观上并行,微观上串行。
- 在宏观的线程层次(调度的基本单位),通过时间片划分、抢占/非抢占策略、就绪/挂起队列等一系列软件设计手段让多个任务并行
- 在微观上的指令层次,不同的指令仍是串行(这里不考虑底层的指令并行技术如多核心调度、超长指令字等),即一个时钟周期内仍只运行一条指令,通过极短的时间片划分和不断的上下文切换来让宏观层次看起来像并行
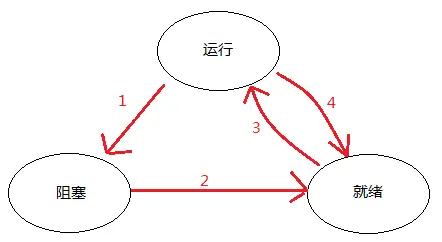
然而,在前面我们提到JS是单线程的,解释器和渲染管线互斥地使用一个线程,显然不能直接套用操作系统的多线程模型来实现代码并行,但我们仍可以借鉴操作系统的线程队列思路。
我们可以为某些“等待态”的任务设计一个挂起队列,即在调用栈外再维护一个“任务队列”(暂且把它称为callback queue)用于存储可能产生阻塞但无需让程序等待的任务,在这样的任务进入调用栈后就放入挂起队列中,解释器继续运行下一行代码,这样就可以既保持JS解释器原有的特性,一次性执行完全部代码,又保持页面的响应性。
如何唤醒沉睡的任务
我们现在让这些任务等待了,但是又迎来了新的问题,该怎么唤醒呢?答案还是藏在我们熟悉的OS里:消息机制和事件响应。
- 操作系统维护一个事件循环来监听事件的发生,监听到事件后(比如鼠标点击、键盘输入等)会向应用程序发送消息,存放在对应的消息队列中
- 应用程序维护一个消息循环来监听消息队列中是否有新消息到达,将消息分发给对应的事件处理函数(handler)
- 如果没有注册处理函数(在消息映射表中未找到),该消息最终会被丢弃。
参考OS的设计,我们也可以在浏览器环境中加入类似消息队列和事件循环机制来处理异步式调用的请求和事件,具体来说就是在JS引擎和渲染线程外单独再开一个线程,维护事件和消息循环与队列。
事件循环是如何实现的
首先,我们要明确一个概念,事件循环本质上是一个任务调度器,和操作系统的线程调度是对等的。
然后,要知道事件循环是什么、做了什么,我们就要首先明白浏览器在渲染和执行一个网页的时候做了什么。
总结上文,我们可以得到一个浏览器的结构至少需要实现三个常驻线程:
- JS引擎线程(JS解释器,如V8)
- 渲染线程(处理DOM,渲染页面)
- 消息线程(处理消息和事件)
其中JS引擎是单线程运行JS脚本的;渲染引擎由于DOM是临界资源所以和JS引擎是互斥的;消息线程则是独立于二者存在的一个循环体,作用就是反复检查挂起队列的任务,并在JS线程空闲(执行栈为空)的时候将挂起队列中的回调函数压入执行栈。
可以说事件循环(event loop)就是消息线程的主要任务,它的任务就是处理这些回调函数的执行。
运行流程
可以说事件循环就是浏览器的消息机制,因此它也有自己的消息队列数据结构,我们叫它Callback Queue(或者说Event Queue, Message Queue)都行。
然而JS解释器依然是单线程的,它只能通过引入一些其他线程来实现自己的异步执行,因此最后的工作流程就变成了下面这样:
- JS解释器照常一口气执行完所有需要执行的JS代码
- 遇到异步调用如
fetch,setTimeOut时,就会把他们的执行权交给Web API(浏览器环境,这里可能不止一个线程来执行这些任务)管理(虽然JS解释器是单线程的,但我可以把它的任务交给另亿个线程啊 (浏览器环境,这里可能不止一个线程来执行这些任务)管理(虽然JS解释器是单线程的,但我可以把它的任务交给另亿个线程啊,阿巴阿巴~~,阿巴阿巴~~)) - 当Web API完成了某个异步任务(如
fetch或click)时,就会把对应的回调函数放入Callback Queue中等待。 - 在执行栈为空时,事件循环把Callback Queue中的队首任务放入执行栈中,回到第一步。
- 在执行完这些命令的解释器空档期(后面会详细解释)就把DOM控制权交给渲染线程,更新UI
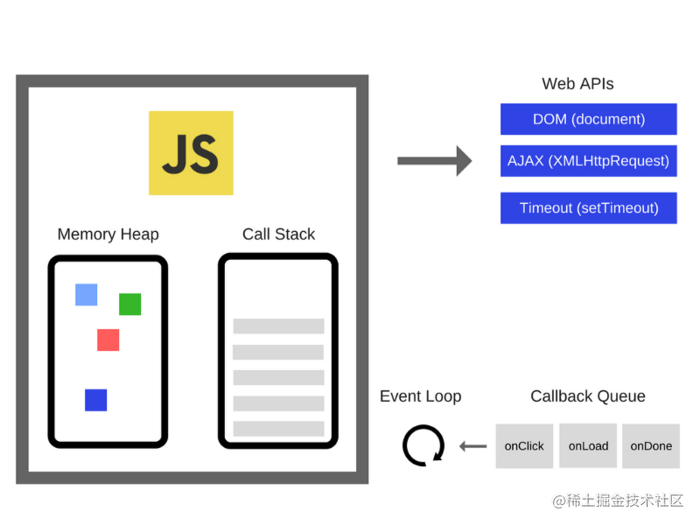
可以在网站Javascript Online Playground上看到JS事件循环中各数据结构的动态过程,如下图所示:
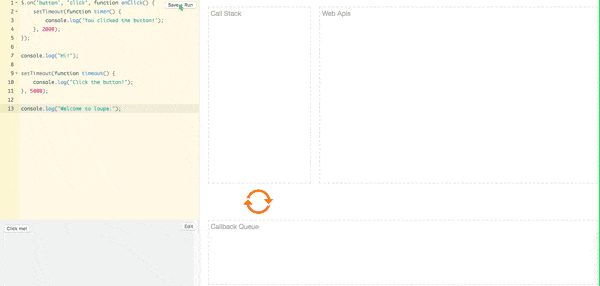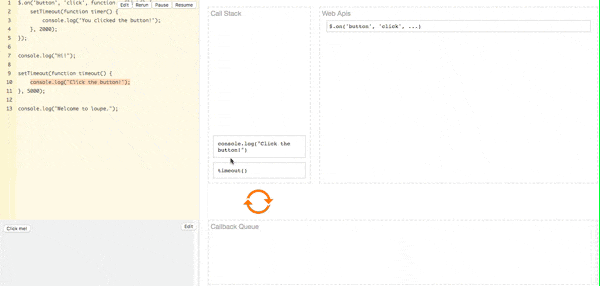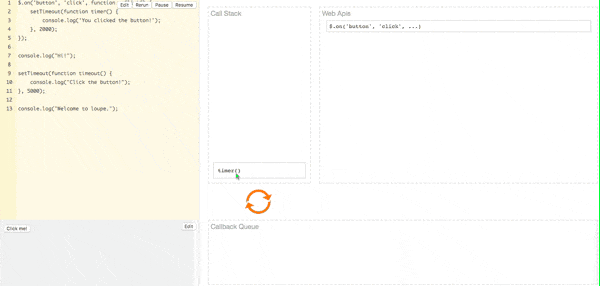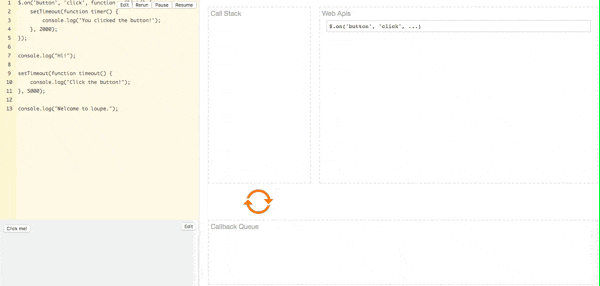
引入事件分级机制(宏任务与微任务)
在实际的生产应用中,对所有的异步任务都一视同仁显然是不合理的,毕竟操作系统里都有优先级队列呢,更强调响应和交互的网页理应对更重要的事件有更高的响应优先级(如IO、UI变化等),为此我们也为浏览器的消息队列(Callback Queue)引入了自己的优先级队列:宏任务(macrotask,如**<script>、setTimeOut)和微任务(microtask,如Promise****)**。
二者的执行顺序如下:
- 首先检查并执行一个宏任务(一般来说第一个宏任务是
<script>标签),并按JS引擎的规矩一次性执行完毕宏任务的所有同步指令,这个过程中可能注册若干个宏任务和微任务 - 当执行栈为空且引擎空闲时(一般来说就是一个宏任务执行完毕的状态),事件循环优先检查和执行Callback Queue中的微任务,注意宏任务是一个一个地执行的,但微任务会一次性清空队列中所有的微任务
- 执行完一个宏任务+微任务的循环后,将DOM控制权交还给渲染线程,更新界面
- 再次检查执行队列,取出一个宏任务执行
常见的常见的**宏任务(macrotask)**宏任务(macrotask) 有: 有:setTimeOut、setInterval、setImmediate、<script>、I/O操作、UI渲染等
常见的常见的**微任务(microtask)**微任务(microtask) 有: 有:Promise、process.nextTick等
例题
console.log(1)
setTimeout(() => {
console.log(2)
}, 0)
Promise.resolve().then(() => {
return console.log(3)
}).then(() => {
console.log(4)
})
console.log(5)正确答案:1 5 3 4 2
- 首先执行宏任务,打印1 5,入列一个
setTimeOut宏任务,一个Promise微任务 - 然后检查微任务,执行第一个
then(),打印3,再入列一个Promise微任务 - 执行第二个
then(),打印4 - 无微任务,执行宏任务,打印2
Note:
这个地方我犯了一个错误,在Promise的第一个then()里我认为return的值是console.log的回调,并没有实际执行,但实质上这里返回的是console.log(3)作为表达式计算后的值,如果要返回回调应该写return () => console.log(3),这样3就不会被打印出来
现代浏览器模型
现代浏览器不仅是多线程(任务共享资源,拥有独立上下文,靠切换上下文实现并行)的,还是多进程(资源彼此独立)的,模型也比上面的基本模型复杂得多(Chromium的内核代码量据说和操作系统相当)。
在Chrome浏览器中,一个标签页就对应了一个进程,每个进程都有自己独立的线程模型:
- GUI 渲染线程
- JavaScript 引擎线程
- 定时触发器线程
- 事件触发线程
- 异步 http 请求线程
参考资料
- javascript - 一文看懂浏览器事件循环 - 脑洞前端 - SegmentFault 思否
- 消息机制与事件处理_消息事件管理_It_sharp的博客-CSDN博客
- Linux操作系统--消息队列_zthgreat的博客-CSDN博客
- javascript - 浏览器与Node的事件循环(Event Loop)有何区别? - Fundebug - SegmentFault 思否
- 浏览器事件循环机制(event loop) - 掘金 (juejin.cn)
- 浏览器事件循环看这一篇就够了 - 掘金 (juejin.cn)
- 浏览器与Node的事件循环(Event Loop)有何区别? - CNode技术社区 (cnodejs.org)