

关于前端和Javascript的模块化,其实已经了解了不少,也写了挺多内容了:
- 在 前端包管理器 - npm 一文中讲了前端模块化的前世,为什么要做模块化,以及模块化和包管理的最初方案
- 在 再谈模块化:Node中ESM与CJS的解析策略 中再次深入了解了CJS和ESM两种主流模块化策略的爱恨情仇,并梳理了Node(Runtime)、TS(Compiler & LSP)和模块策略(CJS/ESM)的三角关系
但是,距离完全弄清现代前端模块化还差最后一块拼图——打包工具(如webpack)对模块的处理以及模块在浏览器中真正的运行方式。
之前已经知道了ESM作为语言层面的模块标准,在现代浏览器中可以使用 <script type="module"> 和 import-map 来启用原生的ESM支持,但是在面向实际生产环境的前端开发时,要面对千千万万用户千奇百怪的浏览器,我们显然不会直接使用ESM,而是会靠像webpack这样的打包工具对语法进行降级、对模块进行处理,最后打包成一个一个的script bundle在浏览器中运行。
那么,我们的最后一块拼图就是这些bundle到底是个啥?他们是靠什么样的机制构建和运行的?
浏览器中的模块化
平时做工程开发的时候,接触到的最复杂的模块化问题可能就是ESM和CJS的互操作问题了,最多就是在处理某些库的时候会看到UMD产物,根本没有操心过这些模块是如何在浏览器中实际跑起来的,只知道webpack会帮我把这些模块全塞到一起,在浏览器中跑起来。
实际上这里面也有一些复杂的门道,我们能岁月静好只是webpack一直在替我们负重前行罢了。
模块化策略的历史
我们都知道最后模块化都会统一成ESM,但是在ESM「大一统」之前,也有「春秋战国」的割据纷争。
| 时间与历史 | 策略 | 主要环境 | 典型实现 | 描述 |
| 2009由NodeJS提出,用于解决服务端JS模块化问题 | CommonJS | NodeJS | NodeJS | 通过模块约定+一层JS patch+文件系统调用实现了模块化 |
| 2009提出,用浏览器异步标准解决模块化问题 | AMD (Asynchronous Module Definition) | 浏览器 | RequireJS | 基于回调实现异步模块引用,强调依赖前置定义 |
| 2011由玉伯提出,与CJS标准类似 | CMD (Common Module Definition) | 浏览器 | SeaJS | 与AMD强调依赖前置不同,CMD与CJS类似,强调运行时按需引入,可以说是浏览器的CJS |
| 2014提出,用于弥合不同模块化策略的差异,提供统一的接口 | UMD (Universal Module Definition) | 浏览器/NodeJS | UMD就是一段胶水代码,底层支持CJS/AMD/CMD,检测到哪种就使用哪种,都没有就直接挂在全局变量上 | |
| 2015随着ES6一起推出,官方下场在语言层面实现的模块化策略 | ESM (ECMA Script Module) | ALL(语言标准) | Native/SystemJS | 语言层次的模块方案,与引擎结合,异步实现 |
下面是一些范例代码:
// CJS语法
// math.js
module.exports = {
add: function(a, b) {
return a + b;
}
};
// use.js
const math = require('./math');
console.log(math.add(1, 2)); // 3
// AMD 语法
// math.js
define(['dependency'], function(dependency) {
return {
add: function(a, b) {
return a + b;
}
};
});
// use.js
require(['math'], function(math) {
console.log(math.add(1, 2)); // 3
});
// CMD语法
// math.js
define(function(require, exports, module) {
exports.add = function(a, b) {
return a + b;
};
});
// use.js
define(function(require) {
var math = require('math');
console.log(math.add(1, 2)); // 3
});
// UMD语法
// math.js
(function(root, factory) {
if (typeof define === 'function' && define.amd) {
define([], factory);
} else if (typeof module === 'object' && module.exports) {
module.exports = factory();
} else {
root.math = factory();
}
}(typeof self !== 'undefined' ? self : this, function() {
return {
add: function(a, b) {
return a + b;
}
};
}));
// use.js
// 取决于环境,可以用AMD、CommonJS或全局变量的方式使用
console.log(math.add(1, 2)); // 3
// ESM语法
// math.js
export function add(a, b) {
return a + b;
}
// use.js
import { add } from './math';
console.log(add(1, 2)); // 3为什么只剩下了CJS和ESM?
从上面的示例代码可以看出,除了CJS和ESM外十分简洁,其他的模块化语法都要编写大量的模板代码,而人总是懒惰的,追求最高效的写法,因此自然就被扫进了历史的垃圾堆。
但是虽然手写起来很麻烦,这些模板代码其实都可以由一些工具自动生成,所以就变成了现在的样子:
- ESM是语言标准,也是未来大一统的模块规范,因此获得了服务端和浏览器的第一方支持
- CJS由于使用方便且有大量npm包使用,长时间内还是会获得支持,且webpack这样的构建工具也使用了类似CJS/CMD的自建模块语法
- UMD由于其良好的兼容性,可以在不同环境中运行良好,因此仍然和构建工具结合使用,用于生成在浏览器中可以直接使用的产物
- 其他模块策略基本已经在现代项目中绝迹了,很少见到了
展开谈谈 UMD
UMD (Universal Module Definition) 是一种模块化定义规范(spec),旨在弥合不同模块规范(除了ESM)之间的差异,让模块在任何地方都可用。
按理来说它应该只是一个规范,应该像其他规范一样有一些样板实现,但是它没有,原因就是它太简单了,没有实际上的「模块加载器」,只是一层薄薄的「胶水层」。
所有能满足所有模块兼容的实现都可以是UMD,一个经典的实现是基于AMD并添加了CJS兼容,如下所示:
(function (root, factory) {
if (typeof define === 'function' && define.amd) {
// AMD环境
define(['dependency1', 'dependency2'], factory);
} else if (typeof exports === 'object' && typeof module === 'object') {
// CommonJS环境
module.exports = factory(require('dependency1'), require('dependency2'));
} else {
// 浏览器全局环境
root.MyModule = factory(root.Dependency1, root.Dependency2);
}
}(typeof self !== 'undefined' ? self : this, function (Dependency1, Dependency2) {
// 模块的实际实现
var MyModule = {
doSomething: function() {
return Dependency1.method() + Dependency2.method();
}
};
return MyModule;
}));它做了以下工作:
- 根据运行时的某些特征来判断具体使用了哪种模块标准,并执行对应的处理
- 提供了一个默认的兜底选项,这让其可以在浏览器中直接使用,这也使其成为了大部分预期在浏览器中直接运行的CDN脚本的最佳选择(直到现在也被大量使用)
但是需要注意的是,由于ESM是语法层面而非应用层面的模块语法,这导致UMD没法检测到其语法特征,无法对其兼容。
再看webpack
之前对webpack的理解都集中在「自定义」上,即对loader和plugin的定制,用于处理复杂的资源处理、分块逻辑等。但是这些工具本质上都是利用webpack暴露的接口在做二次开发,实际上都是第三方工具的工作,而忽略了对webpack自身工作的研究。
总的来说,除了暴露出相关接口让第三方工具对构建逻辑和资源处理逻辑进行自定义外,webpack的核心功能可以分为三部分:
- 模块依赖图构建,解析读取不同类型的模块
- 组织模块形成bundle,处理分块冲突等逻辑
- 构建自己的模块运行时,让应用在浏览器中跑起来
模块解析(resolve)
webpack虽然跑在node上,但没有直接使用node的模块解析算法,而是实现了自己的模块解析算法https://github.com/webpack/enhanced-resolve,可以通过 config.resolve 进行配置,这也解释了为什么有的情况Node不能解析但webpack没问题。
其对比Node的解析算法主要有下面的区别:
- 使用一个resolver解析所有模块格式,而不像node那样对CJS和ESM要使用不同的loader
- 通过callback同时支持了同步和异步加载,而node中require是完全同步的,import是完全异步的
在webpack使用自己的resolver解析模块时,主要做了以下工作:
- 根据node的规则解析模块的具体位置,如处理目录导出、package.json逻辑、缺省拓展名等逻辑,具体作用就是从
identifier(标识符)定位到具体文件 - 根据模块类型(如umd、cjs和esm),在模块被读取到内存中前做预处理,都转换成一种类似CJS格式方便后续处理(都使用
module.exports和require语法,但替换成webpack自己的实现)
具体对于模块的处理,会对非CJS模块进行特殊的标记和处理,如下代码所示:
// ESM 模块
// source.js
export const name = 'hello';
import { other } from './other';
// webpack转换后
"./src/source.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__); // 标记为ESM
/* harmony export */ __webpack_require__.d(__webpack_exports__, {
/* harmony export */ "name": function() { return name; }
/* harmony export */ });
/* harmony import */ var _other__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/other.js");
const name = 'hello';
}),
// CommonJS 模块
// cjs.js
module.exports = {
name: 'hello'
};
// webpack转换后
"./src/cjs.js": (function(module, exports) {
module.exports = {
name: 'hello'
};
}),
// UMD模块
// Webpack处理后
module.exports = (function(module, __unused_webpack_exports, __webpack_require__) {
// 注入模拟环境
var define = undefined; // 禁用AMD
var require = __webpack_require__;
return (function(root, factory) {
// 强制走CommonJS分支
return factory(__webpack_require__("jquery"));
})(window, function($) {
return {
// 库的内容
};
});
});webpack-runtime
webpack在解析和处理模块后,需要将所有用到的模块都打包成一个bundle,然后运行入口文件JS代码,在整个过程中,webpack需要保证在运行时能正确处理所有的模块解析请求,也就是说webpack需要在运行时模拟一个自己的模块化环境——webpack-runtime。
从webpack产物看runtime
我们先看看webpack构建出的产物,来理解整个runtime的模块系统是如何工作的。
下面的样本经过了AI处理,删去了一些无关代码,并将变量更换成了更容易理解的命名:
(function(modules) {
// 模块缓存
var installedModules = {};
// webpack的require实现
function __webpack_require__(moduleId) {
// 1. 检查模块是否在缓存中
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 2. 创建新模块并放入缓存
var module = installedModules[moduleId] = {
i: moduleId, // 模块ID
l: false, // 是否已加载
exports: {} // 模块导出内容
};
// 3. 执行模块函数
modules[moduleId].call(
module.exports, // this指向
module, // module参数
module.exports, // exports参数
__webpack_require__ // require参数
);
// 4. 标记模块已加载
module.l = true;
// 5. 返回模块的导出
return module.exports;
}
// 定义__webpack_require__的一些辅助函数
// 处理ESM的标记函数
__webpack_require__.r = function(exports) {
Object.defineProperty(exports, '__esModule', { value: true });
};
// 定义getter函数
__webpack_require__.d = function(exports, name, getter) {
Object.defineProperty(exports, name, {
enumerable: true,
get: getter
});
};
// 启动入口模块
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})
/******/ ({
// 模块定义对象
"./src/index.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
var _math__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/math.js");
console.log(Object(_math__WEBPACK_IMPORTED_MODULE_0__["add"])(1, 2));
}),
"./src/math.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
__webpack_require__.d(__webpack_exports__, "add", function() { return add; });
__webpack_require__.d(__webpack_exports__, "minus", function() { return minus; });
const add = (a, b) => a + b;
const minus = (a, b) => a - b;
})
});可以看到,webpack的产物主要包含runtime和module map两个部分:
module map:以webpack自己的模块定义格式存储了所有模块依赖
- 使用闭包来实现模块隔离
- 并没有使用UMD,而是使用了类似CJS/CMD的模块策略(
require和module.exports),并替换为了webpack自己的实现
runtime:由webpack在浏览器中维护一个模块化运行时,模拟了CJS流程
- 为每个模块注入必要的运行时上下文
- 创建一个已加载模块的缓存,防止重复执行副作用
- 定义和执行入口模块
分块和分包
在webpack构建模型中,块(chunk)和包(bundle)是两个不同的概念:
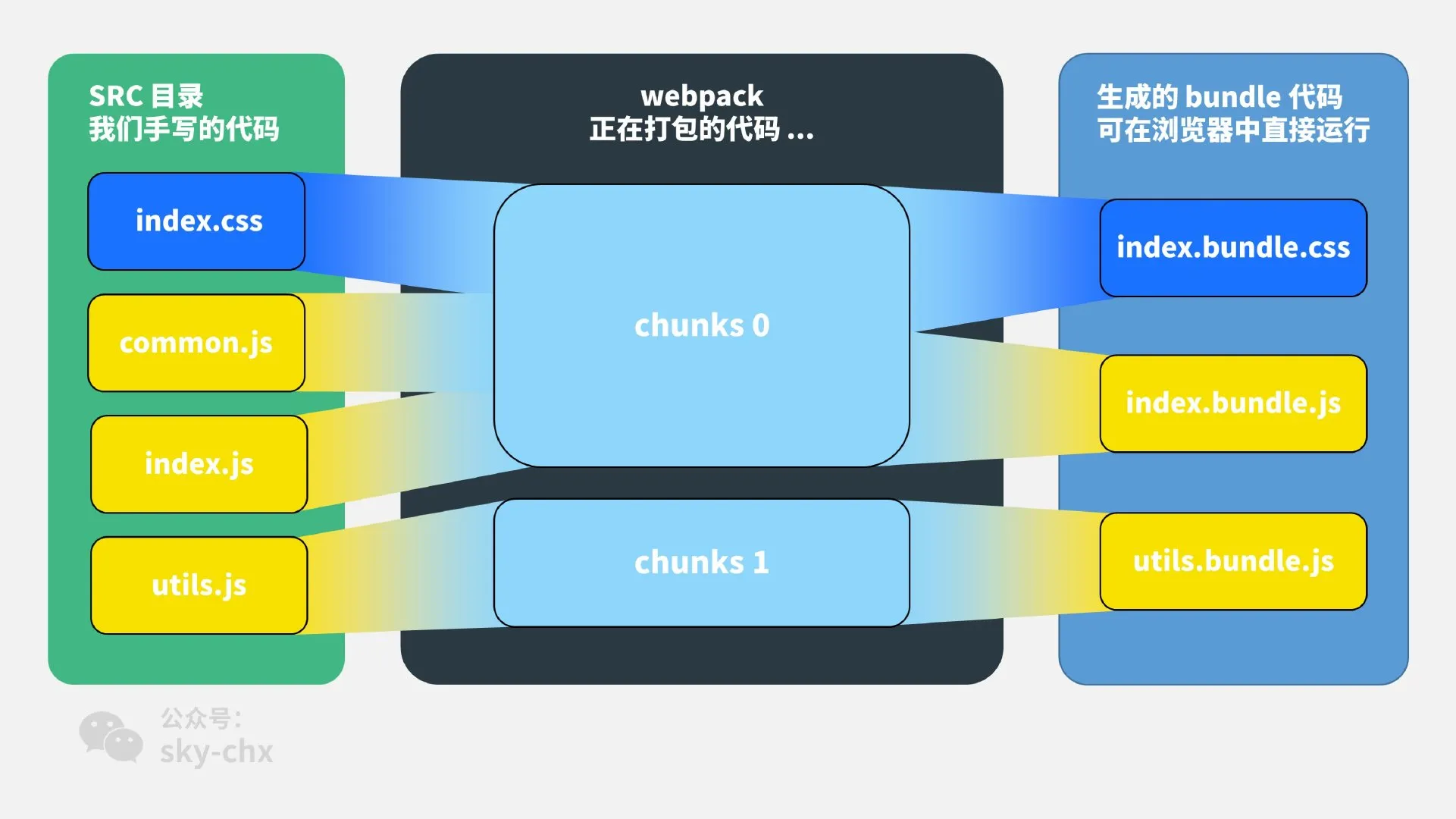
要理解这两个概念,我们要补充一些webpack的基本概念:
- Module(模块):每一个引用的文件都是一个模块,不局限于JS资源
- Chunk(块):每个入口及其所有依赖组成了一个chunk
- Bundle(包):实际的打包产物,默认一个chunk对应一个bundle,可能根据插件情况变化
在实际生产构建中,我们往往需要将整个js入口分成若干个小文件,利用HTTP1.1的多路复用并行加载,提高网络加载效率,这个过程就是代码拆分(code splitting),在webpack中又有「分块」和「分包」的区别:
分块(chunk split):在模块解析和构建时的临时代码集合,chunk是代码分割的最小单位,产生chunk的场景如下
- 定义独立的入口(entry)
- 动态导入(
import()) - 通过 SplitChunkPlugin 定义,如vendor产物
- 分包(bundle generate):chunk最终构建的产物,chunk和bundle是n对n关系,即1个chunk可能生成n个bundle,1个bundle也可能包含n个chunk
当产物中出现多个bundle时,webpack就要做以下工作确保依赖都被正确加载:
- 全局(window)维护一个模块注册表,将不同bundle里的模块都汇总于此(公共runtime)
- 确保不同bundle按顺序执行,避免主入口运行时找不到模块,可以通过同步或
defer脚本实现 - 确保动态导入不阻塞执行,一般通过
async脚本实现,即通过async让其加载好后自动添加到全局模块注册表
以下是实际生成的runtime代码的简化注释版,通过AI提高了代码的可读性:
(() => {
"use strict";
// 模块存储
const moduleDefinitions = {}; // 模块定义对象
const moduleCache = {}; // 模块缓存对象
// 模块加载函数
function require(moduleId) {
// 如果模块已经在缓存中,直接返回
const cachedModule = moduleCache[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 创建新模块并缓存
const module = moduleCache[moduleId] = {
exports: {}
};
// 执行模块代码
moduleDefinitions[moduleId].call(
module.exports,
module,
module.exports,
require
);
return module.exports;
}
// 存储待处理的chunk
const deferredModules = [];
// chunk加载状态
const chunkLoadingState = { 121: 0 }; // 初始chunk状态
// 处理chunk加载完成的回调
function webpackChunkCallback(_, [chunkIds, modules, runtime]) {
let result;
// 注册新模块
for (const moduleId in modules) {
if (Object.hasOwnProperty.call(modules, moduleId)) {
moduleDefinitions[moduleId] = modules[moduleId];
}
}
// 执行runtime代码(如果有)
if (runtime) result = runtime(require);
// 标记chunks为已加载
for (let i = 0; i < chunkIds.length; i++) {
const chunkId = chunkIds[i];
if (chunkLoadingState[chunkId]) {
chunkLoadingState[chunkId] = 0;
}
}
return require.O(result);
}
// 设置全局chunk加载处理
const chunkLoadingGlobal = self["webpackChunkumd_test"] = self["webpackChunkumd_test"] || [];
// 保存原始push方法并重写
chunkLoadingGlobal.forEach(webpackChunkCallback.bind(null, 0));
chunkLoadingGlobal.push = webpackChunkCallback.bind(null, chunkLoadingGlobal.push.bind(chunkLoadingGlobal));
// 添加必要的工具方法
require.O = (result, chunkIds, fn, priority) => {
// 简化的chunk依赖处理
return result;
};
})();可以看到,webpack通过 webpackChunkumd_test 这个全局变量挂载不同的chunks。
Tree Shaking
得益于ESM模块语法的静态特性,webpack支持在构建时对模块进行静态分析,删除产物中模块导出了但是没有实际使用的代码,来减少bundle的体积,
但是,由于依赖于ESM模块语法的静态性,动态导入如 import() 和 require 就不支持Tree Shake了。Rollup虽然支持CJS Tree Shake,但是只支持一部分静态 require 语法,本质上是把CJS换成ESM来解析的。
具体的Tree Shake实现过程有点类似于依赖图(有向无环图)染色问题,即在模块导出被使用时作标记,最后去掉没有被标记的部分,具体实现这里就不再阐述。