深入理解 React Hooks
深入探讨React Hooks的设计原则、实现机制及其在函数式组件中的应用,强调声明式渲染的优势,并提供自定义Hooks的实现示例,如useAsync,用于处理异步请求和状态管理。
2019年2月,React 16.8更新了一大波重磅内容,其中就包括函数式组件(function component)和Hooks,这一象征着React未来方向的技术。没想到已经四年多过去了,我仍对Hooks的理解处于一个皮毛状态,今天我就来深入研究一下React Hooks,探索Hook机制在前端声明式渲染框架中的具体应用。
本文将从为什么要从类组件转向函数式组件和Hooks谈起,理解Hooks的设计原则和目的;再简单谈谈Hook的原理和实现机制来理解Hooks的规则;最后将实现几个自定义Hook加深对Hooks的理解。
为什么需要Hooks
这是一道经典的面试题,但这个问题更好、更全面的呈现方式应该是:为什么要从类组件转向函数式组件和Hooks?
在之前的面试中,我的回答是这样的:
函数组件比类组件更契合React声明式渲染的设计理念,使前端工程更专注于组件树和数据流本身的设计来实现逻辑,而不过分关注副作用(生命周期钩子)来实现业务逻辑,这种模式更直接、更有利于项目的健康。同时由于Hooks的存在,可以在函数式组件中获取一些额外的功能。
其实总的来说,这个回答已经十分到位了,也是我个人的理解,然后面试官的问题通常会在这里结束,转而问你一般用过哪些Hooks,有什么应用场景这些问题。
但我觉得这还不够,总感觉还有一些比较隐秘的问题萦绕在我的心头,因此我们就从一些根本的概念入手,看看react的发展历史来解答困惑。
什么是声明式渲染
与声明式渲染相对的是命令式渲染,即你通过指令去告诉程序怎么一步步地绘制界面,注重于过程的实现;而声明式则是你去绘制一个模板,这个模板接收数据并自动绘制和更新界面,更关注原因和结果本身。整体类似于原生JS或jQuery(命令式)和React(声明式)的对比,有点像命令式编程和函数式编程的概念区别。
总结起来,声明式渲染就强调一个公式:view = render(viewModel)
但是,前端并不是单纯的数据呈现,还需要有交互性,因此这里需要引入一个响应式更新的因素,将viewModel分为不变的props和可变的state两部分:
view = render(props, @reactive states)就此,我们可以建立一个全局的响应式规则:无论什么原因导致state变化,自动触发局部的render函数重新执行。
render props和高阶组件
在函数组件和hooks出世之前,react一直没有找到好的概念和范式来反映上述声明式渲染公式,反复在OOP的框架内兜兜转转,提出了很复杂的类组件,各种生命周期函数来实现业务逻辑,却又没法很好地处理不同组件间的逻辑复用。
在以前的react中,如果你有两个组件都要使用同一个逻辑,如在聊天工具中,发送按钮和头像框都订阅了“用户是否在线”这个逻辑,那么要复用这个逻辑就只有两个方案:
- 复制两份一样的代码,这肯定是下下之策
- 将共同逻辑提升到二者最近的公共父组件层,添加一层没有任何实际渲染功能的抽象层组件
显然,在以前的react中主流的解决方案是第二种,也就是这里说的render props和高阶组件。
顾名思义,render props就是render()函数接收的props参数,这些props由另一个组件传来(也就是说父组件把自己的state作为props传给子组件进行渲染),搭配高阶组件就可以实现抽象层组件,下层组件只负责接收抽象层的数据进行渲染。
下面是我从知乎抄的一段代码(因为我没怎么用过类组件嘿嘿)
// withUserStatus.jsx
const withUserStatus = (DecoratedComponent) => {
class WrapperComponent extends React.Component {
state = {
isOnline: false
}
handleUserStatusUpdate = (isOnline) => {
this.setState({ isOnline })
}
componentDidMount() {
// 组件挂载的时候订阅用户的在线状态
userService.subscribeUserStatus(this.props.userId, this.handleUserStatusUpdate)
}
componentDidUpdate(prevProps) {
// 用户信息发生了变化
if (prevProps.userId != this.props.userId) {
// 取消上一个用户的状态订阅
userService.unSubscribeUserStatus(this.props.userId, this.handleUserStatusUpdate)
// 订阅下一个用户的状态
userService.subscribeUserStatus(this.props.userId, this.handleUserStatusUpdate)
}
}
componentWillUnmount() {
// 组件卸载的时候取消状态订阅
userService.unSubscribeUserStatus(this.props.userId, this.handleUserStatusUpdate)
}
render() {
return <DecoratedComponent
isOnline={this.stateIsOnline}
{...this.props}
/>
}
}
return WrapperComponent
}
// userDetail.jsx
import withUserStatus from 'somewhere'
class UserDetail {
render() {
return <UserStatus isOnline={this.props.isOnline}>
}
}
export default withUserStatus(UserDetail)
这样的形态相对于已经用惯了函数式组件的我来说显然是不健康的,凡事都提一个抽象层出来确实难顶,事实也证明,当你的项目越来越复杂,你的wrapper最终可能会变成这样:
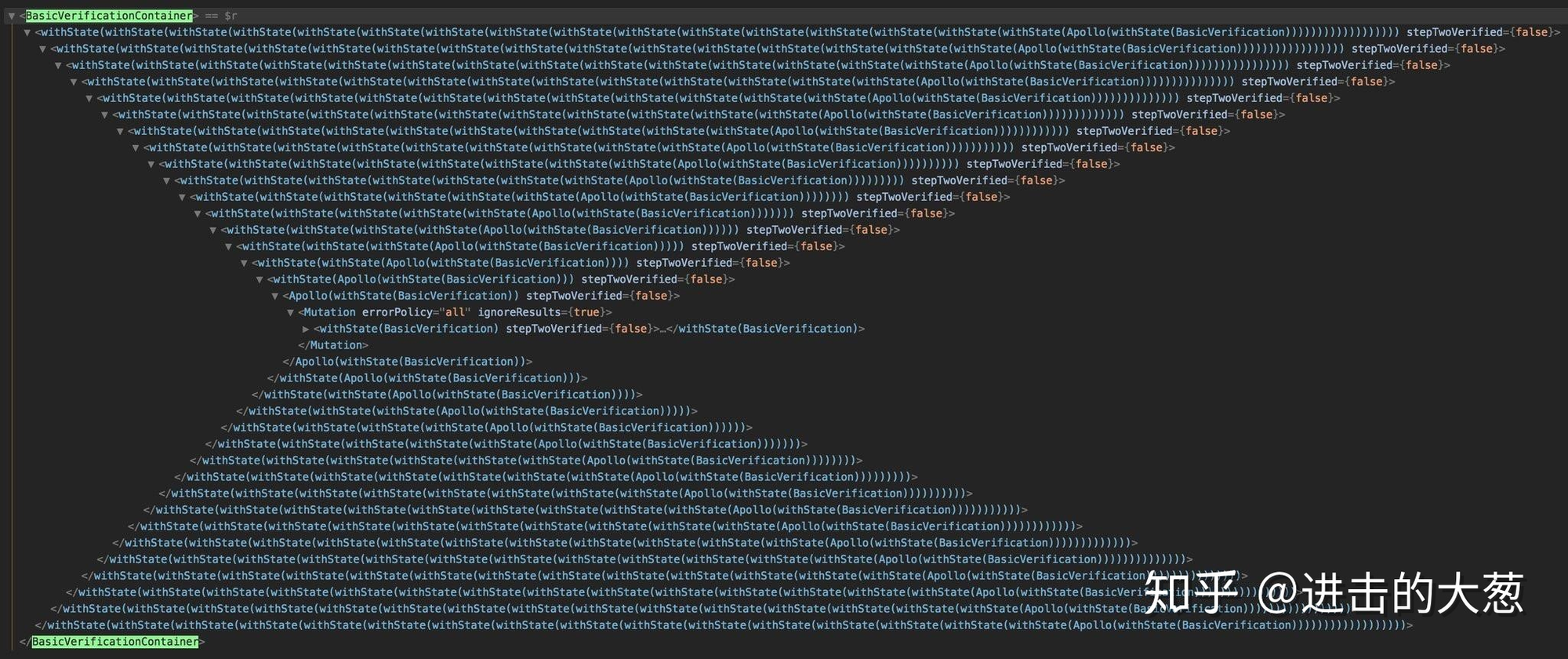
顺带提一句,如果熟悉hooks的同学可能会觉得这和复杂项目中各种provider很像,但这里必须澄清的是:**复用状态(数据流管理)和复用逻辑(hooks)**是两个不同的概念,逻辑也需要在视图层添加额外的组件是不健康的!
Hooks的优势
首先,hooks的出现弥补了函数式组件(纯渲染组件)相对类组件的劣势:开发者偏向于使用Class Component而不是Function Component的一个主要原因是Function Component没有状态管理和生命周期函数等功能。Hook出来后这个问题就不存在了,因为开发者可以使用useState Hook来在Function Component使用state以及useEffect Hook来实现一些和生命周期函数类似的功能。
除此之外,React还将所有复杂的实现都封装在框架里面了,开发者无需学习函数式编程和响应式编程的概念也可以很好地使用Hook来进行开发。
但这些都不能算实打实的好处,hooks的出现还对开发效率有很大的提升,个人的理解有下面几点:
- Hooks的出现解放了函数式组件,在react中彻底干掉了this(
众所周知js的this设计就是XXXX) - Hooks允许你以更方便的方式抽象和提取组件逻辑,而不再需要提取复杂的抽象高阶组件
因此,在现代的react开发中,核心概念可以总结为下面一句话:
函数式组件(纯函数)负责渲染数据,Hooks负责封装和调用业务逻辑(状态管理则是数据流管理,在声明式渲染中不可避免地会留存在树形结构中)
深入理解Hooks的两条规则
React Hooks有两条家喻户晓的规则:
- 只在最顶层使用 Hook
- 只在 React 函数中调用 Hook
但是,在被问到(美团面试)之前,我都对这两条规则没有深入的理解,不知道为什么要有这两条规则,现在就来从实现原理来探讨一下它们产生的原因。
为什么只能在顶层调用
为了理解hooks,我们先实现一个自己的useState和useEffect:
// useState.js
var _state; // 把 state 存储在外面
function useState(initialValue) {
_state = _state || initialValue; // 如果没有 _state,说明是第一次执行,把 initialValue 复制给它
function setState(newState) {
_state = newState;
render();
}
return [_state, setState];
}
// useEffect.js
let _deps; // _deps 记录 useEffect 上一次的 依赖
function useEffect(callback, depArray) {
const hasNoDeps = !depArray; // 如果 dependencies 不存在
const hasChangedDeps = _deps
? !depArray.every((el, i) => el === _deps[i]) // 两次的 dependencies 是否完全相等
: true;
/* 如果 dependencies 不存在,或者 dependencies 有变化*/
if (hasNoDeps || hasChangedDeps) {
callback();
_deps = depArray;
}
}
可以看到,我们使用闭包(词法作用域)实现了简单的useState和useEffect的逻辑,但他们还有一个显著的弱点:的逻辑,但他们还有一个显著的弱点:**只能调用一次,在不同的地方调用他们都会使用同一个全局变量。**只能调用一次,在不同的地方调用他们都会使用同一个全局变量。 那么react是如何解决这个问题的呢?答案很简单: 那么react是如何解决这个问题的呢?答案很简单:通过有序表(数组/链表)——我们把全局变量变成一个数组,这样不就可以存储更多的值了吗?
let memoizedState = []; // hooks 存放在这个数组
let cursor = 0; // 当前 memoizedState 下标
function useState(initialValue) {
memoizedState[cursor] = memoizedState[cursor] || initialValue;
const currentCursor = cursor;
function setState(newState) {
memoizedState[currentCursor] = newState;
render();
}
return [memoizedState[cursor++], setState]; // 返回当前 state,并把 cursor 加 1
}
function useEffect(callback, depArray) {
const hasNoDeps = !depArray;
const deps = memoizedState[cursor];
const hasChangedDeps = deps
? !depArray.every((el, i) => el === deps[i])
: true;
if (hasNoDeps || hasChangedDeps) {
callback();
memoizedState[cursor] = depArray;
}
cursor++;
}
至此,我们也获得了我们的答案,这也是为什么react官方说:只有在顶层调用我们才能确定hooks调用的顺序正确,而上面的解释也让我们理解了为什么要保证hooks的调用顺序正确——因为react在刷新时会按照初次渲染的表顺序对数组中的元素进行比对和更新,如果不在函数顶层我们就无法确认每次刷新(重新加载组件)时调用hooks的序列是完全相同的。
对具体过程感兴趣可以参考这篇博客:React Hooks 原理 · Issue #26 · brickspert/blog (github.com)
这里再引用一句话,它很好地从另一个角度(设计而非技术实现)概括了Hooks这条规则的本质:
为什么Hooks需要限制只能在代码的第一层调用 Hooks,不能在循环、条件分支或者嵌套函数中调用 Hooks?
因为本来它应该写在参数区的,只是因为语法的限制导致它没有专有的位置而已。
我来解释一下就是Hooks作为逻辑实现,它本来不应该出现在函数组件中(就类似于直接在函数组件中定义和使用了高阶组件)。由于JSX没有语法的限制,导致它能出现在任何地方,但理论上它应该作为不变的props传入组件中(就像render props那样),所以才会对其做出这样的限制。
为什么只能在React函数内使用Hooks
这看起来是一个比较蠢的问题,显然是因为react函数(函数组件和hook函数)提供了普通js函数没有的功能,但它是如何实现的呢?
这又指向了另一个问题:刚刚我们的简单hook其实也只能在一个组件中反复调用,如果有多个组件也不能成功地记忆state,那要如何才能实现真正的useState和useEffect呢?为了解释这个问题和两个问题之间的关联,我们仍需要从react的底层实现谈起。
首先,在react中,每次调用hook实际上会生成一个Hook的数据结构,并以单链表(而非数组的形式)组织起来:
export type Hook = {|
memoizedState: any,
baseState: any,
baseQueue: Update<any, any> | null,
queue: UpdateQueue<any, any> | null,
next: Hook | null,
|};
而在fiber架构中,组件树中所有节点构成了一个单链表,每个节点对应一个组件,hooks 的数据就作为组件的一个信息,存储在这些节点上,伴随组件一起出生,一起死亡。

说到这里,你是不是想到了这两个问题其实指向了一个共同的回答:react函数提供了一个普通js函数没有的作用域(上下文),而这也是通过js的词法作用域(闭包)实现的!
那么,我们的声明式渲染式公式也可以随之进一步完善一下,加入一个隐式的context元素用于实现hooks,现在函数式组件可以通过闭包机制来灵活地切换上下文,实现每个组件都有自己的hook序列:
view = render(props, @reactive state, @implicit context)
那么,在react中实际上的调用过程是怎么样的呢?我们以useState为例看看:
useState内部会调用ReactCurrentDispatcher.current.useState- 由于hook一定只会在另一个hook或函数组件中调用(也就是说外面一定包着一个函数组件),而只有在函数组件执行前才会将
ReactCurrentDispatcher.current设置为HooksDispatcherOnMount或HooksDispatcherOnUpdate - 当函数组件执行完后
ReactCurrentDispatcher.current马上被设置为ContextOnlyDispatcher - 所以在 React 函数外使用
useState时,useState内部会调用ContextOnlyDispatcher.useState,该函数是会报错的。其他 hooks 同理。
因此,react实际上是通过闭包机制去设置全局变量实现了每个函数组件有自己的hook上下文,这也让自定义hook执行起来就像直接把hook内容宏替换到指定位置再运行一样(因为与执行环境上下文是统一的)。
实现自己的Hooks
秉承着hooks是对业务逻辑的抽象与封装(对render props和高阶组件的替换),我们就开始着手将组件中涉及副作用的逻辑抽象成自定义hooks方便复用。
useAsync的实现
“如何使用自定义Hook实现每次访问这个Hook都访问的是同一个对象?”
—— MHY一面
上面这道题在问我的时候我其实并没有真正答出来,但其实是我当时的理解有误:我认为是想让不同的组件访问该Hook都拿到同一个值。所以我当时提出的方案是在另一个地方存储这个数据,如:服务器、localStorage或闭包(全局变量),并提出了我的质疑——我认为Hook只应该对逻辑进行封装,不应该直接对状态进行管理(应该结合Context来实现)。
但是现在换一个思路,如果是说让Hook能记忆住某个状态,并在调用时可以想起这个状态,使其返回同一个实例(即只调用一次,有点像单例模式),那么这个Hook的实现就是有意义的,而调用异步资源的Hook:useAsync则正是这样一个Hook。
构建简单环境
首先我们先用koa后端+react前端搭建一个简单的环境(包管理器我使用pnpm,使用其他包管理器不影响操作),以便进行实践:
pnpm+vite+swc的组合真的充满了现代气息,相比守旧派的cra(npm+webpack+babel)真的快了不止半点。
- 首先初始化简单的后端环境
$ mkdir server-test
$ cd server-test
$ pnpm init
$ pnpm add koa
- 修改后端环境代码(来自koa官方的hello world用例),这回创建一个始终返回Hello Koa(不管什么url、什么方法)的socket。
// index.js
const Koa = require('koa');
const app = new Koa();
// response
app.use(ctx => {
ctx.body = 'Hello Koa';
});
app.listen(3000);
- 修改启动代码,在
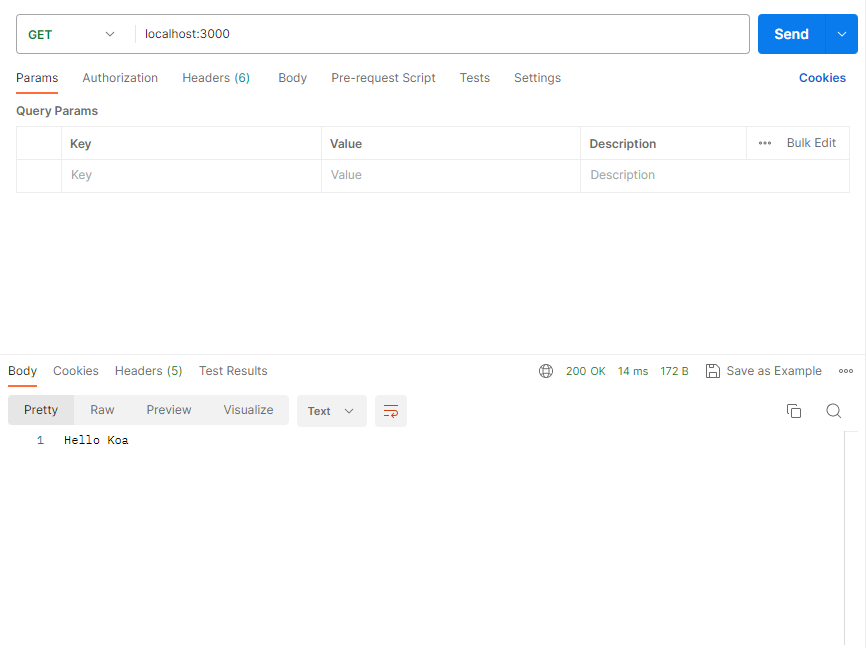
package.json中修改启动脚本:"start": "node index.js" - 启动后端服务,在postman中测试如下图所示表示成功:
- 初始化前端项目,这里使用vite和axios
$ cd ..
$ pnpm create vite
# 创建完成后切换到项目目录
$ pnpm install
$ pnpm add axios
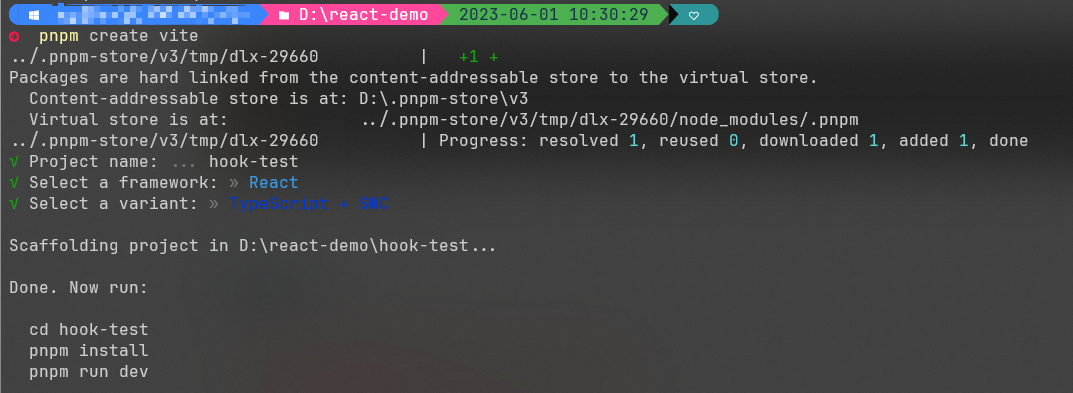
注意这一步中的提示命令如下图所示,注意选择react+typescript+swc:
- 配置vite代理,具体代码如下:
// vite.config.ts
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react-swc'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [react()],
server: {
proxy: {
'/api': 'http://localhost:3000'
}
}
})
- 修改./src/App.tsx代码,配置基本的异步fetch
// App.tsx
import { useState } from 'react'
import reactLogo from './assets/react.svg'
import viteLogo from '/vite.svg'
import axios from 'axios'
import './App.css'
function App() {
const [count, setCount] = useState(0)
const [resp, setResp] = useState('')
axios('/api')
.then((res) => res.data)
.then((data) => { setResp(data) })
.catch((err) => { console.log(err) })
return (
<>
<div>
<a href="https://vitejs.dev" target="_blank">
<img src={viteLogo} className="logo" alt="Vite logo" />
</a>
<a href="https://react.dev" target="_blank">
<img src={reactLogo} className="logo react" alt="React logo" />
</a>
</div>
<h1>Vite + React</h1>
<div className="card">
<button onClick={() => setCount((count) => count + 1)}>
count is {count}
</button>
<p>
Edit <code>src/App.tsx</code> and save to test HMR
</p>
</div>
<p className="read-the-docs">
Click on the Vite and React logos to learn more
</p>
<p>{resp}</p>
</>
)
}
export default App
如果所有步骤都成功了,运行pnpm run dev可以看到如下的结果(注意后端不要停),看到Hello Koa就算成功了。

useRef的本质
useRef 是一个 React Hook,它能让你引用一个不需要渲染的值
此前对useRef的理解也仅限于官方文档中推荐的为DOM绑定ref来实现一些对dom的直接操作,一直没有深入地了解。
之前对ref的理解就只有以下两点,都是不求甚解的阶段(不知道为什么,但是直到怎么用):
- 在JS中声明ref只需要
const el = useRef()即可,但在TS中则需要(以Input为例)const el = useRef<HTMLInputElement>(null)。需要注意的是,这个*null*很重要,没有null就会报错! - 在不同组件中传递ref时需要使用forwardRef而不能直接传递ref,即用
forwardRef(renderer)把组件包裹起来,子组件中可以直接获取ref
正如官网介绍所说,useRef可以创建一个无需渲染的值的引用,返回一个只有current属性的对象,将ref传给DOM只是ref的一种用法(react自动给current赋值),你也可以将ref用于存储一些其他与渲染无关的值。
- “无需渲染”意味着 ref 只是一个普通的 JavaScript 对象,改变它的值不会引发重新渲染。
- 但是ref和真正普通的JS对象也不同:普通JS对象每次重新渲染都会重置,而ref永远只会初始化一次,因此ref可以用于存储一些需要在渲染之间保持的值
- ref和state/memo是两种不同的存值方案,ref主要用于不需要呈现在ui上的值
但react不建议(但不阻止)在渲染期间(包括return中和前面的逻辑部分)手动改变ref的值(托管给dom的除外),因为根据声明式渲染的原则,你的props+state+context一致时,返回的view就应该是一致的,而在渲染期间修改了非响应式的变量导致渲染结果发生改变显示是非期望的行为。
总的来说,ref就是一个游离于响应式的存储方案,在某些场景如存储内部id(计时器、调用等),操作dom API等很有用,也是我们实现单例调用的基石。
实现简单的useAsync
当年看别人写的useAsync就觉得很神奇,怎么做到把Promise抽出来做成一个state的,年少的我百思不得其解,现在理解了hooks后发现不过是把loading和state绑定的逻辑封装了起来(就是把Promise.then中的setState封装了起来),但需要注意的是:不应该重复请求资源,在组件释放后不应该继续更新状态,这些功能都要结合其他hooks实现。
第一个功能可以靠useMemo和useCallback进行缓存;第二个功能则可以靠useRef和useEffect去记录当前组件是否还被加载。
下面的代码将实现一个简单的useAsync,通过输入Promise注册,直接在返回的state中显示状态、错误和数据:
import { useState, useRef, useEffect, useCallback } from 'react';
type Status = 'idle' | 'pending' | 'resolved' | 'rejected';
interface IRequestState<T> {
status: Status;
data: T | Error | null;
}
function useMountedRef() {
const mountedRef = useRef(false);
useEffect(() => {
mountedRef.current = true;
return () => {
mountedRef.current = false;
};
});
return mountedRef;
}
export default function useAsync<
T = unknown,
Args extends unknown[] = unknown[]
>(fn: (...args: Args) => Promise<T>) {
const [state, setState] = useState<IRequestState<T>>({
status: 'idle',
data: null,
});
const mounted = useMountedRef();
const setData = useCallback(
(data: T) => setState({ status: 'resolved', data }),
[]
);
const setError = useCallback(
(error: Error) => setState({ status: 'rejected', data: error }),
[]
);
const updateData = useCallback(
async (...args: Args) => {
setState({ status: 'pending', data: null });
if (mounted.current) {
try {
const ans = (await fn(...args));
setData(ans);
} catch (error) {
setError(error as Error);
}
}
},
[fn, mounted, setData, setError]
);
return [state, updateData] as const;
}
在这个示例中,我们封装了一个async逻辑,获得一个回调函数,返回它的状态和更新handler。
在调用端我们做以下调整,这样就会在第一次加载页面时加载数据(mount周期而不是update周期),更进一步地我们可以把对axios的封装和首次加载页面获取数据也抽象成hook,这里就不再赘述:
const tryFetch = async () => {
const resp = await axios('/api');
return resp.data;
};
const [{ data, status }, update] = useAsync(tryFetch);
useEffect(() => {
update();
}, [update]);
使用别人的轮子
在自定义hooks方面,除了官方提供的hooks是必须了解的,其实已经有很多成熟的第三方库提供了很多实用的hooks。
参考资料
- 从React Hooks看React的本质 - 知乎 (zhihu.com)
- 前端进阶系列——理解 React Hooks - 知乎 (zhihu.com)
- React为什么需要Hook - 知乎 (zhihu.com)
- 为什么React Hooks会有两条使用规则 - 掘金 (juejin.cn)
- React Hooks 原理 · Issue #26 · brickspert/blog (github.com)
- 为什么React要用函数式组件? - 掘金 (juejin.cn)
- 怎么理解“声明式渲染”? - 知乎 (zhihu.com)
- React设计模式-Render Props - 知乎 (zhihu.com)
- Hook 规则 – React (reactjs.org)
- useRef – React
- 使用 ref 引用值 – React
- React自定义hook之useAsync处理异步请求并实现自动执行回调函数_无响应乱码元素的博客-CSDN博客
标题: 深入理解 React Hooks
作者: ChlorineC
创建于: 2023-06-01 15:08:00
更新于: 2025-01-11 21:00:00
版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。