前端包管理器 - npm
本文介绍了前端包管理器npm的发展历史、功能和重要性。npm不仅是一个包管理器,还是前端项目管理的基础,管理依赖、项目信息和脚本。文章详细探讨了npm的历史、模块化概念、依赖管理的演变,以及如何使用npm管理项目和发布自己的npm包。尽管npm在现代前端开发中逐渐被yarn和pnpm等新工具取代,但其核心思想和机制仍然对开发者有重要的学习价值。
重写计划
本文拆分为两个部分
js模块化方案分析
- 浏览器模块化规范 AMD/UMD
- Node模块化规范 RequireJS → CommonJS
大一统规范 ECMA Module(ESM)
- 浏览器支持
<script type="module"> - Node16+原生支持ESM,Node22支持Require和ESM互操作
- 浏览器支持
工具链的重要成分Node和TS解析模块的细节
- tsconfig中的相关参数,在npm包开发和web开发中的区别和推荐配置
- package中的相关参数
npm的发展史和用法
- 前端包管理器的发展
- node_modules的变迁
- 后现代时代
- 竞争带来进步
本篇文章是前端工具链系列文章的开篇之作,本来是打算写一篇很长很长的文章,来详尽阐述2023年的前端工具链的全貌的。但奈何篇幅实在太长,不便发布和阅读,而且有些部分完成度已经较高,但由于其他部分的完成度几乎为0导致这些内容不能发布出来 (可以预见的由于工作原因另一部分可能拖更较久) 。
最终选择了分段分章节的形式,将每个部分单独提出来说,最终在一个目录中汇总,这样阅读体验更好,每个部分也能说得更详细一点。
本篇主要讲述npm的发展历史(历史渊源和各个版本的改动),组织node_modules方式的变动以及package.json的详细介绍(并发布一个自己的npm包);除此之外,还会介绍node官方提出的现代包管理器愿景,并介绍corepack工具(包管理器的管理器)。
<!-- more -->
npm(Node Package Manager) 不仅是一个包管理器,更是前端的项目管理器,它除了管理依赖,还定义了项目的信息、脚本和行为,这些信息都被npm存储在package.json中。
可以说npm是一切前端项目,包括其他包管理器的基础,其他包管理器均必须实现npm的基础功能,你可以没有其他包管理器,但你必须有且理解npm。
上面一段是我在 上面一段是我在 《前端工具链》**《前端工具链》 草稿中写的原文,虽然这一段在新的组织形式下已经不再合适作为部分总结,但仍很好地概括npm的地位——理解了npm你才能理解其他包管理器(或者说为什么需要更现代的解决方案),也是为什么我们已经有yarn和pnpm等更现代的解决方案,连node官方都打算不再完整内置npm的今天我们仍需要学习npm的原因,而不仅仅是出于一些兼容性的原因才学习和使用npm(当然学习了npm的机制也能更好地解决出现在其他包管理器中出现的兼容性问题)。 草稿中写的原文,虽然这一段在新的组织形式下已经不再合适作为部分总结,但仍很好地概括npm的地位——理解了npm你才能理解其他包管理器(或者说为什么需要更现代的解决方案),也是为什么我们已经有yarn和pnpm等更现代的解决方案,连node官方都打算不再完整内置npm的今天我们仍需要学习npm的原因,而不仅仅是出于一些兼容性的原因才学习和使用npm(当然学习了npm的机制也能更好地解决出现在其他包管理器中出现的兼容性问题)。
npm的诞生
如果你用过C++,也用过Python或者Rust,那你在 如何快速地调用他人写好的代码 这件事上,对二者的效率有深刻的认识。是的,Python/Rust有自己的包管理器(pip/cargo),但C++却没有一个统一的包管理器方案(vcpkg或许是一个选择),这导致你调用别人代码的门槛显著提高,也不利于库作者的版本管理。
程序员群体从最初开始就强调一个社区文化、开源精神 程序员群体从最初开始就强调一个社区文化、开源精神 (Bill Gates除外)(Bill Gates除外) ,复用别人的代码和让别人能复用自己的代码自然也是社区的头号需求,在现代前端开发中node环境已经普及的今天(或者说昨天),一个对应node环境的包管理器自然会产生,是的,这就是npm。 ,复用别人的代码和让别人能复用自己的代码自然也是社区的头号需求,在现代前端开发中node环境已经普及的今天(或者说昨天),一个对应node环境的包管理器自然会产生,是的,这就是npm。
拿Python作对比的话:JavaScript是语言本身,类似于python;node是语言运行环境,类似于cpython;npm是包管理器机制,类似于pip(和PyPi)。
其实在项目管理这一点上,node.js和npm更像Rust于Cargo的关系 但是说爸爸像儿子总是不合适的
前npm时代如何共享代码
毕竟JS和Web的历史远比Node和npm更悠久,那么在更为原始的web开发年代,大家是如何共享代码的呢?
对于直接使用代码来说,有两种方法:
- 直接共享代码:在Github上共享代码库,直接下载源码,也就是最直接的使用方式
- 使用CDN分发:现在的网页开发中仍存在这种方法,即用
<script src="xxx"/>直接引用线上的JS资源
JS模块化
如果我们采用上面提到的两种方法对他人的代码进行复用,在项目规模不断扩大后,新的问题就出现了:全局变量污染。
假如说我们用<script>引入了a.js和b.js两个JS脚本,但两个脚本中都定义了一个名称相同的全局变量,或者都使用了隐式的全局this指针去给同一个属性赋值,这时的变量行为就不再可控了,彼此覆盖的顺序通常由<script>的执行顺序决定,这可能会给整个页面的效果造成毁灭性的破坏。
一个比较简单粗暴的解决方案是给每个全局变量都加上模块名前缀,并禁止使用全局this,但这显然是一个治标不治本的方法,只有从根本上解决全局作用域的问题才能维持项目的健康,这里就需要引入“模块化”的概念。
模块化:把复杂的系统分解到多个模块以方便编码
在模块化编程中,开发者将程序分解成离散功能块(discrete chunks of functionality),并称之为模块。
- 将一个复杂的程序依据一定的规则(规范)封装成几个块(文件),并进行组合在一起
- 块的内部数据相对而言是私有的,只是向外部暴露一些接口与外部其他模块通信
每个模块具有比完整程序更小的接触面,使得校验、调试、测试轻而易举。 精心编写的模块提供了可靠的抽象和封装界限,使得应用程序中每个模块都具有条理清楚的设计和明确的目的。
JS的所谓模块化就是包装一个模块内部的所有代码,使其标识符不向外暴露,而仅仅暴露声明(导出)的标识符,以避免全局污染。为了实现模块化的这些功能,Web界提出了不同的解决方案:
原始的
<script>方案 + 开发规范:这种方案并不能称得上严格意义的模块化,仅仅是引用了不同的JS文件,并遵守了一定规范- 仍可能污染全局作用域,script会直接存在在根DOM下,全局有效
- 仅适用于Web页面开发,在node环境中无效
- 在大型项目中各种资源难以管理依赖、版本和加载顺序
- CommonJS系列方案:Node的主流方案,使用模块作用域来解决全局污染,都使用
require来引用模块 - ESM方案:采用 方案:采用 “编译时输出接口”****“编译时输出接口” 的策略,是一种静态的、异步的、底层的模块化方案 的策略,是一种静态的、异步的、底层的模块化方案
CommonJS 家族
CommonJS方案有CJS、AMD和CMD三个分支方案,这里推荐只了解CJS方案即可。由于CJS目前最主流的平台实现是NodeJS,因此大部分特性将依照Node的实现机制进行理解。
CommonJS(CJS)方案:在ECMA Module(ESM)方案出来前最流行的方案,现在NodeJS仍采用这种方案作为主流,但Node 12后也官方支持了ESM,只是需要一些手段来启用其支持(如.mjs后缀名或指定type: module)
AMD和CMD是CJS方案在浏览器端的异步实现,这里不再介绍。
- CJS是一种同步加载方案,模块的加载顺序,按照其在代码中出现的顺序进行加载
CJS添加了一种模块作用域(类似于C语言中的单文件作用域),每个文件就是一个模块,所有代码运行在模块作用域中,不会污染全局作用域
- 通常情况下模块内声明的变量不会污染全局作用域,除非意外声明了全局变量(没有用
var,let,const关键字而直接声明) "use strict"模式可以避免上述情况,但可以通过global.XXX显式地声明全局变量- Node中使用包装函数为每个文件提供了一个独立的函数作用域,以此来实现了模块作用域,详见这篇文章
- 通常情况下模块内声明的变量不会污染全局作用域,除非意外声明了全局变量(没有用
使用
require(package)加载模块(即被依赖模块的module.exports对象)- 通过按顺序查找PATH去加载模块
- 模块可以加载多次,第一次加载时会运行模块,模块输出结果会被缓存,再次加载时,会从缓存结果中读取输出模块
缓存机制可以通过先创建缓存再载入文件的顺序避免循环引用产生的死锁
- 当
app.js调用a.js时,发现第一行是加载b.js,它会检查缓存中有没有b.js,发现没有,于是 new 一个b.js模块,并将这个模块放到缓存中,再去加载b.js文件本身 - 在加载
b.js文件时,Module 发现第一行是加载a.js,它会检查缓存中有没有a.js,发现存在,于是require函数返回了缓存中的a.js - 这个时候
a.js根本还没有执行完,还没走到module.exports那一步,所以b.js中require('./a.js')返回的只是一个默认的空对象。所以最终会报setA is not a function的异常
- 当
使用
module.exports对象暴露当前模块对外的接口(是的,module.exports是一个对象)- 直接将一个对象赋值给
module.exports,require时就可以直接获取这个对象 - 也可以给
module.exports添加属性或方法,如module.exports.foo = 'foo' - 为了方便,Node为每个模块提供一个
exports变量,即在开头隐式地提供了exports=module.exports这样一句话
- 直接将一个对象赋值给
每个模块内部都包含一个
Module对象(自动生成)id:模块的标识符filename:模块的文件名,带有绝对路径loaded:表示模块是否已经完成加载,用于缓存加载parent:一个数组,表示调用该模块的模块children:一个数组,表示该模块要用到的其他模块exports:一个对象,表示模块对外输出的值
- 由于CJS需要Node的支持,在浏览器端需要转译为*
<script>*标签才能使用,但其模块作用域将得到保留,全局污染的问题得到了解决 - 由于CJS的所有功能都是用JS已有特性实现的,因此你也可以实现自己的CJS函数
在本地跑了一个demo,一个空文件的CJS Module变量如下:
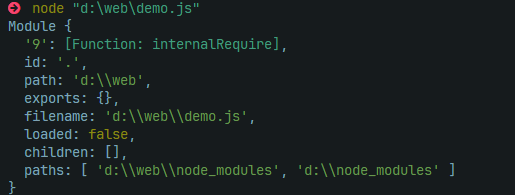
ESM 模块
在CommonJS家族中:CJS是同步加载,主要用于服务器端(Node)的模块化实现;AMD、CMD是异步加载,二者处理依赖的方式不同,主要用于浏览器端的模块化实现。但他们都有一个共同点:他们都只是在JS现有功能基础(如闭包)之上实现的模块化,而不是语言层面的模块化,因此也有很多因此而生的缺点:
module和exports并非JS关键字,而仅仅是对象或函数,其实现由具体的运行时或者库决定(如Node),并非统一的语言标准- CJS为了保证加载顺序的可控,采用同步加载(即同步地执行模块内部全局作用域地代码来初始化模块),可能造成阻塞和性能瓶颈
- 最重要的一点:由于实现机制的原因,CJS的
require返回的是值的拷贝(执行代码直接将对应值赋给exports对象)
其中最难的是**如何理解CJS的****require**返回的是值的拷贝,请参考下面的代码——由于拷贝了值,无论如何setVal始终都不能改变val的值(具体过程详见这篇文章):
// a.js
let val = 1;
const setVal = (newVal) => {
val = newVal
}
module.exports = {
val,
setVal
}
// b.js
const { val, setVal } = require('./a.js')
console.log(val); // 1
setVal(101);
console.log(val); // 1
为了解决上述问题,ECMA出手了,在ES6标准中提出了ESM模块规范,它在CJS规范上更进一步,在语法层次上为模块化提供了支持,并有自己的语法:
- 使用
import语句进行模块导入,export语句进行模块导出 export分为默认导出和命名导出两种export只能导出一个默认(含有default)值,这个默认值可以用任意名称导入,如import AnyName from './moduleWithDefault'- 使用命名导出可以导入若干个模块内的变量,可以批量命名导出,如:
export {a,b,c} - 命名导出和默认导出可以一起使用
import语句支持不含后缀名的写法(因为不同后缀名可以代表不同的标标准,如.mjs和.cjs)- ESM默认采用严格模式,即全局
this是undefined的,这彻底杜绝了全局污染的可能性(实际上是ES6要求) - ESM模块的是静态的、编译期的,同时也是直接引用而非拷贝,这解决了CJS最大的一个痛点
要理解为什么需要ESM模块,我们就要知道ESM和CJS的根本区别——CJS是对象拷贝,ESM是符号链接,是更底层的东西。
对比CJS和ESM,它们最主要的区别如下:
- ESM是语言标准,
import和export是JS语言关键字,可以在编译期直接输出模块接口,因此说ESM是静态的 - ESM是异步加载的,在执行模块前有一个独立的模块依赖的解析阶段
- ESM中
import返回的是模块的引用而非拷贝,任何对原模块的改动都会即刻反映到所有调用它的地方
在理解ESM的实现之前,我们要先了解一些JS解释器运行JS代码的过程才能更好地理解ESM:
在V8引擎中,JS的执行过程被分为了两个步骤:
编译阶段:将文本代码翻译成更贴近机器的字节码,但仍需要Runtime来执行(解释型语言,非机器码)
- 词法分析:将语句化成一个个Token,这一步可以检出错误的标识符
- 语法分析:注意词法作用域实际上是在语法分析中形成的,这一步可以检测语法错误
- 字节码生成(在编译型语言中这一步是IR或机器码生成)
执行阶段:JS解释器会模仿系统调用和任务队列,为语句和函数创建执行上下文(execution context)并推入执行栈
创建阶段
- 绑定this
- 为函数和变量分配内存空间
- 初始化作用域中所有变量(注意es6中
let和const不会被赋初值undefined)
- 执行阶段:将执行上下文推入执行栈,并开始运行代码
所以,ESM之所以是 所以,ESM之所以是 “编译时输出接口”****“编译时输出接口”,正是因为它是ECMA的亲儿子,可以对编译期本身做手脚。,正是因为它是ECMA的亲儿子,可以对编译期本身做手脚。
由于我确实没有查到“编译时解析引用”相关的资料,以下几点是我个人的理解,并不保证正确。
这里需要明确一点:JS是解释型语言,严格意义上并不存在所谓“编译期”,只有将代码解析生成“字节码”的过程。
- 在模块作用域方面,可以理解为和CJS没有区别(没有找到相关资料)
在编译期(词法、文法分析阶段)ESM的特殊之处在于它在语法层面为
import和export提供了支持,在语法分析阶段会检查顶层规则- 当你违反了
import或export的语法规则,它会在编译阶段就报错而根本不会进入执行阶段(不会生成执行上下文) - 在遇到正确的
import和export时会生成对应的符号链接(并不是真的在编译期就解析了引用),并在后续的创建阶段才将这些符号连接起来,这也是ESM能真正引用模块的原因
- 当你违反了
- 实际解析引用的阶段应该是运行阶段中的创建阶段,而非执行阶段,这也是ESM被称为“静态引用”或者“编译时引用”的原因,因为它确实在运行阶段之前就解析了引用
- 在创建阶段解析的顺序大概是这样:创建词法作用域->变量声明提升->检查变量中的*
import***->进行引用解析**。因此在循环引用时原模块的词法作用域是已经声明好的 - 解析模块引用的过程与CJS相似(先创建缓存实例再加载代码):检查缓存->新建Module实例放入缓存->加载模块代码
下面这段代码证明了ESM确实在编译期为import和export提供了语法支持:
console.log("Wrong Import")
if (true) {
import path from "path"
}
// out:
// import { resolve } from 'path';
// ^
// SyntaxError: Unexpected token '{'
如上面的代码,在报错时根本不会打印log的“Wrong Import”,而是直接显示错误信息,因为程序在编译阶段就报错并Panic了,根本不会进入运行阶段。
而下面这段代码则用循环引用演示了ESM的加载过程,顺带证明了ESM确实是在运行阶段之前进行了模块解析:
// index.mjs
import './a.mjs';
// a.mjs
// 注意这里的运行顺序,如果先运行了这句再运行b中语句就代表是动态加载
console.log('running a.mjs');
import { b, setB } from './b.mjs';
console.log('b val', b);
console.log('setB to bb');
setB('bb')
let a = 'a';
const setA = (newA) => {
a = newA;
}
export {
a,
setA
}
// b.mjs
import { a, setA } from './a.mjs';
console.log('running b.mjs');
console.log('a val', a);
console.log('setA to aa');
setA('aa')
let b = 'b';
const setB = (newB) => {
b = newB;
}
export {
b,
setB
}
上面这段代码证明了EMS的加载过程,注意由于上下文的创建阶段会提升内部所有变量构建词法环境,因此这里可能会发生局部死区或者变量提升问题,但这避免了循环引用导致的死锁。
但当我们直接运行index.mjs可以发现它报错信息如下:
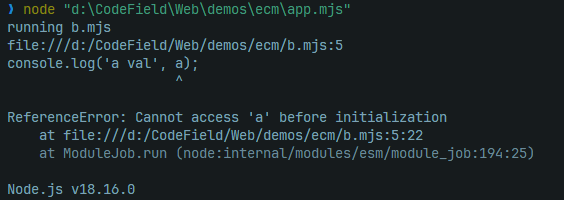
这并不是由循环引用造成的,而是变量提升造成的局部死区,我们将a.mjs顶层变量的声明从let改成const就可以让其获得初始值undefined,并用function替代变量初始化(因为变量提升会初始化function),让这个例子成功的跑起来。(是的,只用改a,因为只有b在调用a时会产生死区)
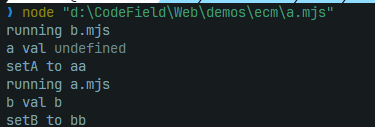
由上面的例子,我们来分析一下整个模块的解析过程:
app.mjs导入了a.mjs这个模块,检查缓存不存在,创建一个Module实例放入缓存中,并加载a.mjs的代码到实例中编译
a.mjs的代码,创建执行上下文,在过程中发现了b.mjs的引用,以同样的方式加载b.mjs的代码- 编译期会检测ESM规则和错误,但并不会实际执行导入工作
在
b.mjs代码的开头发现了a.mjs的引用,返回a的缓存,由于此时a的缓存中模块的执行上下文已经初始化完毕,也就是说变量声明已经提升- 如果是
var变量就会得到初始值undefined - 如果是
function声明的函数就会提前声明和定义 - 如果是
let、const和箭头函数变量,就只会提升定义,并不会得到初始化,出现局部死区错误
- 如果是
- 如果没有发生错误,
b中将会使用a中的执行上下文环境变量继续执行 b的全局执行上下文(不属于任何函数的语句的上下文)执行完毕后退栈,轮到a继续执行,此时b的所有变量都已经正确声明且初始化,因此不会发生任何错误a执行完毕,退栈,控制权还给app,代码执行完毕,程序结束
如何管理模块
现在我们有了完善的模块化方案(CJS和ESM),并将模块的概念进一步扩大:若干源码文件(模块)组成一个代码集合,这个集合可能实现了一组逻辑或功能,我们将这个集合封装起来,并定义一个入口文件,这样整个集合对外就成了一个模块,内容就是入口文件的内容,再在入口文件内选择对外暴露的接口,这个“大模块”内部的组织结构并不会向外暴露,只有“入口模块”向外暴露,这样就形成了包(package)。
npm(Node Package Manager)就是这样一个管理基于NodeJS开发的包的工具,它提供了两项基本功能:
- 项目管理:开发的项目本身作为包应该如何发布和管理
- 依赖管理:当前项目依赖的其他包如何从统一的地方下载和管理
当然,npm-v1中的依赖管理思路是非常简单粗暴的:每个包都声明自己需要哪些依赖,在安装依赖的时候就递归地为所有包安装它的依赖,直到所有包都安装完毕,最终形成了一个嵌套的node_modules结构:
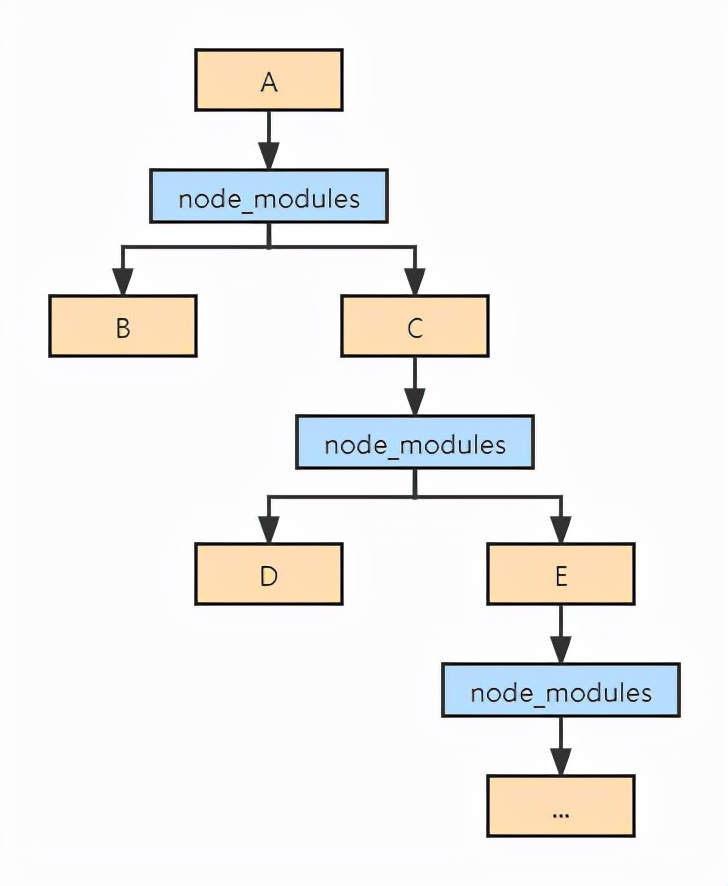
这样做的好处是简单粗暴,不会出问题;坏处就是可能会存在大量重复的依赖,浪费空间,同时在项目复杂度不断增长后路径深度过大可能产生错误。
npm的进化史
粗犷的嵌套目录(v1-v2)
在v1和v2版本,npm一直采用刚刚提到的完全嵌套式的目录结构来管理依赖,产生了大量的空间浪费和过深的目录。
扁平化目录(v3-v4)
在v3版本中,npm为我们带来了扁平化的依赖关系树,把嵌套的目录完全拍扁成一层,解决了重复依赖和目录深度问题:
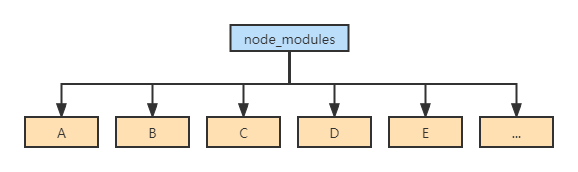
但扁平目录的更新并没有解决全部的问题,它也带来了一些新的问题:
- 扁平化的目录不能正确反映包之间的依赖关系。因此npm必须首先遍历所有的项目依赖关系生成依赖树,再决定如何生成扁平的node_modules目录结构(即在install安装时,会不停的往上级node_modules中寻找,如果找到同样的包,就不再重复安装),而这个依赖分析是一个很耗时的操作,也是npm安装速度慢的一个很重要的原因。
- 依赖结构是不确定的。当两个包依赖了同一个包的不同版本,这在依赖解析时的行为就是无法确定的。如
B依赖了[email protected],而C依赖了[email protected],若在package.json中B在C前面就会采取B的依赖(即[email protected]),否则就会采取C的依赖。 - 由于间接依赖也会放在顶级目录中,因此**项目中可以非法访问没有在****
package.json*中声明过依赖的包
固定化依赖(v5+)
受到了yarn-v1(Classic Yarn)的冲击,npm-v5终于引入了固定化依赖树的文件结构:package-lock.json,它在npm install时会自动生成,比package.json记录了更多的额外信息,可以加快npm install的速度和稳定性。
其实在此之前,npm也有类似的lock文件去记录依赖树信息,叫做npm-shrinkwrap.json,但并不会自动生成,需要使用npm shrinkwrap指令去生成,且向下兼容npm-v2~4,在v5+的优先级也高于lock文件。
lock文件记录了什么
首先,我们先随便打开一个项目的package-lock.json看看里面有什么:
{
"name": "hr-manage-system",
"version": "1.0.0",
"lockfileVersion": 2,
"requires": true,
"packages": {
"": {
"name": "hr-manage-system",
"version": "1.0.0",
"license": "ISC",
"dependencies": {
...
},
"devDependencies": {
...
}
},
"node_modules/@ampproject/remapping": {
"version": "2.2.0",
"resolved": "https://registry.npmjs.org/@ampproject/remapping/-/remapping-2.2.0.tgz",
"integrity": "sha512-qRmjj8nj9qmLTQXXmaR1cck3UXSRMPrbsLJAasZpF+t3riI71BXed5ebIOYwQntykeZuhjsdweEc9BxH5Jc26w==",
"dev": true,
"dependencies": {
"@jridgewell/gen-mapping": "^0.1.0",
"@jridgewell/trace-mapping": "^0.3.9"
},
"engines": {
"node": ">=6.0.0"
}
}
}
}
可以看出,lock文件里的依赖信息显然比package.json更丰富,如指定了明确的版本号、下载地址等信息,最重要的是指定了依赖项的依赖项,这避免了反复查询,节省了大量时间,同时也起到了固定依赖的作用。lock文件的出现,一口气解决了npm-v3中安装构建慢、依赖版本不确定、依赖树不确定的问题。
总结:
- lock 文件可以指定依赖的版本号、下载地址和依赖情况,保证其他人在*
npm install***时大家的依赖能保证一致**并节约安装时间 - 需要保证所有人使用同一份lock文件才能提高效率,避免冲突
- 每次添加新包需要运行一次*
npm install*才能更新lock文件,特别是在其他包管理器和npm共同使用的时候这点非常关键
npm install时发生了什么
要真正理解lock文件是如何起到固定依赖树的作用的,我们就需要知道npm install时究竟发生了什么。之所以放到这里才讲而不是开头,是因为v5这里基本确定了现代包管理器的安装方式,放在这里讲就避免了重复叙述。
首先,我们看一张npm install的总体流程图:
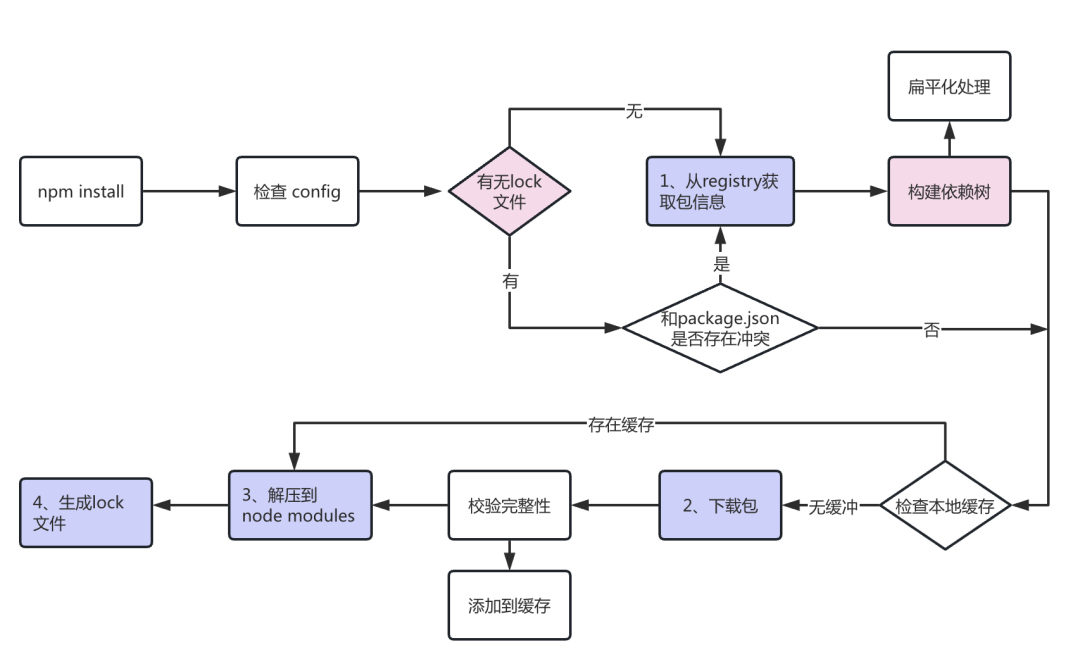
一般来讲,npm install按照上图工作,大致可以分为5个流程:
- 若未找到****
package-lock.json,就依次向cache和registry(线上源)查询包信息;若找到package-lock.json则直接使用其记录的依赖树信息,免去了查询和构建的过程,直接下载对应包(或调取缓存) - 下载依赖包,存放在cache目录
- 解压下载的压缩包到
node_modules目录 - 将所有**已安装的包信息存放到****
package-lock.json*中,以供下次安装使用 - 递归地处理依赖的依赖,直至所有依赖都完成安装
从上面的流程中我们不难看出,lock文件描述的是npm应该从哪里找到、怎么构建依赖的行为集合,如果有lock文件作为指导npm就不用挨个查询,而是一步到位节省很多时间。
但是,如果lock文件和**package.json**产生了冲突,安装过程就无法顺利进行:
- npm 5.0.x版本,不管
package.json怎么变,npm install都会根据lock文件下载。 - npm 5.1.0 - 5.4.1版本,
npm insall会无视lock文件,去下载semver兼容的最新的包。 - npm 5.4.2版本之后,如果手动改了
package.json,且package.json和lock文件不同,那么执行npm install时npm会根据package中的版本号和语义含义去下载最新的包,并更新至lock。
npm的全局缓存
相信细心的同学已经发现上述的npm install中有调取缓存这个操作,但在传统印象中不是yarn才有缓存吗(网络性能优化)?其实不然,其一n是npm很早之前就有了本地下载缓存机制(但一直到v5才支持offline-mode);其二网络性能优化和下载缓存不是同一个概念,并不能相提并论。
这里仅讨论npm-v5后引入的cacache机制。
npm从registry下载任何package时,都会存储到本地的缓存目录:$NPM_PATH$/_cacache里(可以试试用Everything搜索),里面又有三个文件夹:
- content-v2:实际存储tar包的地方(下载缓存)
- index-v5:存放meta信息用于索引
- tmp:临时文件
npm在安装依赖的时候,根据具体包的version, name和integrity信息(通常是直接用lock文件中的)按如下步骤进行计算:
- 按
pacote:range-manifest:{url}:{integrity}的格式生成唯一key - 通过SHA256计算Hash,去
_cacache/index-v5里找对应的索引文件(前4位分目录,分两层),得到meta信息如下:
14da5c6cbf56513e6c9a015428e7a2e967770958 {
"key": "security-advisory:rc:lY0T7yQCamSwv6XrfkWFkNC52rORUpy+EA52ZHNPnNx68d9GVbTXrEorrxRr7Rp5o2tBSHDK27ayPcgCQX8IrQ==",
"integrity": "sha512-rE2QtaXAtFkff+ggY34B7Dned+y7u6eAhuMa19j7MdZe/02nmZLBbgx2lsVHny3KhWUPz367HGA1UMIKzoc2iw==",
"time": 1664882561084,
"size": 881
}
可能还有metadata字段,描述了这个缓存的源信息和Hash值用于比对,这里我随便打开了一个没有这个字段。
- 利用
metadata中的_shasum字段去_cacache/content-v2中匹配gzip缓存 - 如果缓存命中,就会向远程仓库确认是否过期(304检查)检查,如果均通过,就会直接使用缓存;否则就会向registry请求包,并更新缓存。(与浏览器缓存机制类似)
这里有个问题,为什么需要使用两级缓存机制(索引+SHA寻址)而非直接缓存,留待解答。
值得注意的是,npm5中也引入了yarn中的**offline-mode**特性,在此之前是不支持离线安装的
- 使用
-prefer-offline后将优先使用本地缓存 - 使用
-offiline后将强制使用本地缓存,若本地缓存中没有请求的包将会报错
lock 文件再升级(v7+)
npm-v7中提出了许多现代npm中至关重要的更新,但大多围绕着更严格的依赖锁定来开展:
提升*
package-lock.json*的语法版本到v2,提供更确定、更全面的依赖树锁定支持- 安装时**支持解析****
yarn.lock*文件,并在更新package.json时同时更新yarn.lock package-lock.json仍然会生成,且优先级高于yarn.lock,因为yarn本身不同的版本对yarn.lock有不同的解析策略,而package-lock.json则对项目的确定性构建有决定性的作用(不受npm版本的影响)- 在具有 v1 锁文件的项目中使用 npm 7 运行
npm install会将该锁文件替换为新的 v2 格式。若要避免这种情况,可以运行npm install --no-save
- 安装时**支持解析****
修改*
peerDependencies*的安装逻辑:当peerDependencies的版本冲突无法解决时,npm将会阻止安装行为(详见下方)- 当A和B都在
peerDependencies中声明了要和某个版本的C一起使用,但这个版本互不兼容,npm-v7就会阻止安装并抛出错误 - 如果你使用
-legacy-peer-deps选项就会使用之前的安装策略,即仍采用默认的安装顺序去安装依赖,在遇到冲突时只会显示警告而不会阻止安装
- 当A和B都在
- 官方的monorepo和workspace支持(虽然一般不使用npm来管理monorepo)
npm如何管理项目
npm通过根目录下的package.json管理项目,其中定义了当前项目的基本信息(包信息)、自动化脚本和项目依赖,随着npm版本的发展,package.json也变得越来越复杂。
package.json的正确使用姿势
相信写过一些项目的同学都对package.json不会感到陌生,对其大概的理解就是包含了一些包名、命令脚本和依赖包等信息,处于一个知之但不甚的阶段。如果仅仅是开发简单的项目,调用别人写好的包,自然也不需要深究;但如果你的项目体量较大(或者时间跨度较久),抑或你要发布自己的包,那仔细研究 package.json和npm管理项目的机制就很有必要了。
npm工作机制的变迁在上面的部分已经说得比较清楚了,到了v9这一代,除了依赖管理方案外和其他现代包管理器(yarn2和pnpm)其他已经基本接轨了,在项目管理上也是大同小异,因此主要在npm中介绍了项目管理相关后,后面的包管理器介绍中就会主要关注其依赖管理机制和对npm的改进,而不会重复讲述项目管理的知识。
个人看来,package.json中主要说了三件事:
- 别人如何调用我的包
- 我如何开发自己的包
- 我引用了别人的哪些包
当前包信息
所谓当前包信息就是“别人如何调用我的包”和“我引用了别人的哪些包”,其中“别人如何调用我的包”代表性的属性如下,指明了当前包发布到npm所需的信息:
需要注意的是,以下信息如果不发布到npm都是可选的;如果需要发布到npm则只有name和version是必须的。
name: 当前包名,必须是唯一的- 可以有作用域,如@org/packageA
- 不应有大写字母,也不应有URL中不安全的字符
version: 版本号,与name一起构成npm包最重要的两个属性- 如果不发布包到npm的话,name和version其实是可选的
- 遵循semver(语义化版本规范),详见后文
description: 描述信息,可选,列在npm search中keywords: 关键字,和描述信息一样是可选的,也列在npm search中homepage: 项目主页,可选repo: 仓库地址,可选bugs: 反馈bug的地址,接收一个联系方式对象,可选
{
"url" : "https://github.com/owner/project/issues",
"email" : "[email protected]"
}
license: 开源证书,可选- people fields: 开发者相关,接收
author,contributor两个字段,可选 files: 决定哪些文件会发布到npm,可选- npm会寻找根目录下 .npmignore文件,如果没有就用.gitignore代替,他们不会覆盖files字段
- 无论如何始终会包含:
package.json,README,LICENSE,main字段中的文件 - 还有一些文件始终被忽略,这里不再列举
main: 标识包的入口模块,一般用于Node模块而非浏览器- 这里前面JS模块化的知识就派上了用场,在整个模块作为包被引用(import或require)时,
main字段标识的文件将作为目标模块被引用(export) - 在Node(或者说CJS)中,即main指向的js文件(模块)的exports对象会作为整个包的exports
- 在ESM中,即外部import的引用会指向main指定的js文件的export标识
- 这里前面JS模块化的知识就派上了用场,在整个模块作为包被引用(import或require)时,
bin: 告诉npm哪些是可执行文件,在制作CLI工具时尤为有用- 需要在CLI命令相关JS文件第一行添加如下声明告诉系统这个脚本由Node执行:
#!/usr/bin/env node - 声明bin时尽量使用相对路径(. 开头)
- bin接收一个对象,其键值对格式为
alias: path-to-script,当值不是对象时只接收path-to-script,且alias默认是包名(name)
- 需要在CLI命令相关JS文件第一行添加如下声明告诉系统这个脚本由Node执行:
{
"name": "my-program",
"version": "1.2.5",
"bin": {
"my-program": "./path/to/program"
}
}
依赖包信息
虽然“我引用了别人的哪些包”严格来说也是当前包信息的一部分,但由于当前包信息只在发布npm包时才有作用,而依赖包在任何项目管理中都会出现,且其复杂度要更高一些,因此这里单独拿一部分来讨论。
一般来说,项目的依赖(dependencies)在npm中被分为了以下几类:
dependencies:无论开发环境还是生成环境都需要依赖的包,通常是一些库模块(如axios,dayjs等),可以使用npm i <pkg> --save在安装包时就记录下来(实际上安装任何包时都会默认记录到dependencies中)devDependencies:在开发时需要,生产环境中需要的包,通常是一些打包器(如webpack)和转译器(如ts-node),可以使用npm i <pkg> --save-dev来保存到这个part中optionalDependencies:表示这个包是可选的,如果安装失败不会终止安装过程,但需要在应用程序中做相应处理(否则会产生找不到模块的报错),可以使用-save-optional或O来添加peerDependencies: 表示工程需要和这个依赖(的指定版本)配套使用,一般用于插件开发而非项目开发,是为了解决本项目作为包被引入的时候与主项目(或其他依赖)依赖版本冲突的问题(如[email protected]表明了自己需要vue@^3.2.0配套使用),可以使用P选项来添加。bundleDependencies:表示工程在发布时会携带这些modules,而不是每次使用插件时都需要重新使用npm install下载一遍,可以使用-save-bundled或B来添加
SemVer 规范
在继续讨论依赖管理之前,我们先了解一下npm和其他很多包管理器(项目管理)都采用的版本管理规范:SemVer(SEMantic VERsioning,语义化版本规范)命名规范。
不仅你在调用别人的包时需要考虑semver来划定版本范围,在你开发自己的包时也要根据semver来更新版本号。
semver一般由以下四部分组成:
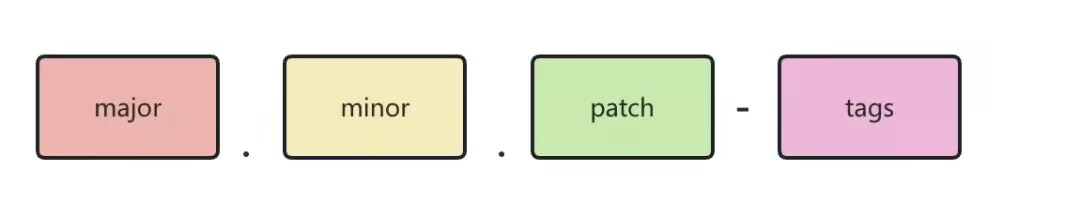
major位:发生了无法向下兼容的API修改minor位:新增了向下兼容的功能patch位:做了向下兼容的问题修复tags标签:用于标记某些先行版本(pre-releases),如alpha.1,beta.2等
遵照semver规范,合法的版本命名有:2.1.0, 3.1.4-beta.2等
如果遵照conventinal commit规范,许多工具都可以根据Git Log中的commit messages自动生成CHANGELOG和更新版本号,如lerna这样的monorepo管理工具。详见我的另一篇博客:
在使用他人的包时,我们也可以使用~, >, <, =, >=, <=, -, ||, x, X, *等符号来锁定和描述版本,以下是常用符号说明。
^是缺省时的默认情况,表示只锁定major,minor和patch取最新版本~表示锁定major和minor,patch取最新版本=表示锁定全部版本>=表示指定一个最低版本,尽可能取最新版本x, X, *表示通配符,如3.4.*
不同种类依赖(deps)的应用
一般来说一般的网页开发中比较常用的就是dependencies和devDependencies,区别在上面也说的比较清楚了。
下面就是一份比较简单的dependencies声明(摘自Vite+React的练手项目),可以看到除了运行时需要用到的库都被放在了devDependencies中,比较典型的有代码格式化工具(ESLint)、TypeScript相关工具还有打包器(如Vite)。
"dependencies": {
"axios": "^1.4.0",
"react": "^18.2.0",
"react-dom": "^18.2.0"
},
"devDependencies": {
"@types/react": "^18.0.37",
"@types/react-dom": "^18.0.11",
"@typescript-eslint/eslint-plugin": "^5.59.0",
"@typescript-eslint/parser": "^5.59.0",
"@vitejs/plugin-react-swc": "^3.0.0",
"eslint": "^8.38.0",
"eslint-plugin-react-hooks": "^4.6.0",
"eslint-plugin-react-refresh": "^0.3.4",
"typescript": "^5.0.2",
"vite": "^4.3.9"
}
这里说一个不太重点的冷知识:CRA(create-react-app)会默认把所有依赖都一股脑安装到dependencies里,而不会区分devDependencies,这是为什么呢?
大家不妨想一想一个CRA网页应用的构建过程:安装依赖→调用依赖→通过Webpack打包和发布网页。
这个过程全程是不是除了依赖管理没有关系,应用也不会发布到npm中,别的应用也不会调用这个包,发布是靠的webpack依赖解析和tree-shaking生成目标JS文件,而如果你要跑这个网页又一定需要安装所有的依赖,因此其实这种不会发布的项目区分devDpendencies的意义不大,只能算一个良好习惯,当然无论如何还是希望能保持一个良好的习惯(毕竟Vite是默认区分了的)。
其他的依赖类型中,bundleDependencies和optionalDependencies在日常开发中几乎不使用,而peerDependencies 则多用于版本冲突问题的解决。
在npm-v2版本中就引入了
peerDependencies字段,但其含义与现在完全不同,而是更贴近原意“对等依赖”,即安装的这些依赖和我是平级的而不是我的子模块,表达的是:“如果你安装我,那么你最好也安装X,Y和Z”- 由于v2中是嵌套依赖结构,依赖的依赖会放在对应的目录中,而不是扁平的node_modules中
- 声明在
peerDependencies中的包会安装在根目录而非当前包的依赖目录中
npm-v3版本改变了依赖组织的形式,变成了扁平依赖项模式,这样就使得v2的
peerDependencies字段显得毫无用处,但扁平依赖又有依赖树版本不确定的问题,因此npm又为它赋予了新的含义:“我需要这个版本的X,构建完成后请检查一下版本对不对”peerDependencies声明的依赖并不会被安装,而仅仅是在安装过程结束后检查是否安装正确- 如果
peerDependencies没有被正确安装,仅仅会发出警告,而不会中止安装 - 从语义上来说,这个版本的peerDependencies更像是“默认使用者使用此包就一定会安装的那些其他包”,如redux包就可以默认使用者一定安装了react,vuex就可以默认一定安装了vue@^2.0.0
- 理解了
peerDependencies只是一个检查,而不是安装,就可以理解其他所有dependencies的优先级都高于peerDependencies和可以重复声明的原因了
- 在npm-v7中,peerDependencies的语义被再次增强,它仍表示那些默认使用者已经安装的包,但当包没有被正确安装时会报错并终止安装,这导致了许多项目在v7以后产生无法安装的错误,使用
—legacy-peer-deps即可回退到v6以前的安装模式
项目管理信息
所谓的项目管理信息就是“我如何开发自己的包”,这其中主要就是使用scripts字段去定义一些脚本(命令组合),快速地对项目进行调试、打包等操作,使用npm run <script>或者对于某些特殊脚本直接npm <script>即可运行对应脚本。
使用scripts定义脚本比直接运行有以下优势:
scripts脚本往往更加简洁,一个单词就可以让npm为你执行一大串指令scripts脚本往往遵循某些约定俗成的规范,可以让不同项目保持一致性,如start,dev,build等- 使用
scripts脚本可以更方便地封装行为,保持项目跨平台的可运行 - 使用
scripts脚本可以直接使用对应包管理器调用相应包并执行对应指令,而不用手动定义包管理器PATH和启动行为
这里涉及到了一些npm-CLI相关知识,在后文会详细提到。
npm scripts是强大且自由的,它可以组合和定义你能想到的几乎任何功能。它的原理很简单,npm在每次执行脚本时会自动新建一个 Shell,在这个 Shell 里面执行指定的脚本命令,且在新建过程中会把 ./node_modules/.bin 加入环境变量(这也是为什么它可以直接使用对应包管理器调用相应包)
一个普通前端项目一般会包括以下脚本:
- start:启动脚本,可以直接使用
npm start调用 - dev:开发环境脚本,一般在不区分生产环境时与start相同(就不重复创建),区分开发环境时则多用于本地环境
- test:测试脚本
- lint:代码检查脚本,可以添加后缀如
lint:es或lint:prettier
除了上述的基础脚本外,npm还提供了一些基于生命周期Hooks的脚本,使用pre*或post*前缀定义,如postinstall ,会在对应生命周期的前/后自动执行。npm默认提供以下Hooks:
- prepublish,postpublish
- preinstall,postinstall
- preuninstall,postuninstall
- preversion,postversion
- pretest,posttest
- prestop,poststop
- prestart,poststart
- prerestart,postrestart
需要注意的是,自定义脚本也支持添加Hooks。
npm-CLI
npm除了在package.json中记录了项目相关的信息,还提供了一系列CLI命令来帮助我们管理项目,自动化包管理流程,在上面的内容或日常使用中我们已经接触到了一些命令,如 npm install, npm start等。
由于npm-CLI实际上是一个比较繁杂的系统,一次性讲完既不现实,也没有必要,这里更推荐的是遇到需求或问题再去文档中查找相关内容。对应地,这里仅仅介绍我日常开发中常用的一些指令:
npm install:安装所有依赖npm install <pkg>/npm i <pkg>:安装指定包npm uninstall <pkg>:删除包npm run <script>:运行指定指令(npm start和npm test不需要run)npm cache clean:清除下载缓存
npm link的使用
npm link的本质是创建一个软链接,用于将本地的包添加到另一个项目中,多用于开发中的包的调试。
工作原理是:将其链接到全局node模块安装路径中。为目标npm模块的可执行bin文件创建软连接,将其连接到全局node命令安装路径中。
- 在需要调试的项目(正在开发的插件)中运行
npm link,将当前包链接到全局 - 在调试环境中运行
npm link <pkg-name>来创建到指定包的软链接
npx指令
设想一个场景,比如你要使用 webpack 来打包,你一般有两个选择:
- 全局安装 webpack,直接使用命令行
webpack直接调用,但这样需要手动更新版本,且不同项目使用同一个版本可能出现冲突和兼容性问题 - 使用本地 webpack,就需要
./node_modules/@webpack-cli/xxx这样的格式,很是麻烦
npx 想要解决的主要问题,就是调用项目内部安装的模块,避免全局安装模块。
使用 npx 后,再调用 webpack 就可以使用下面的格式
$ npx webpack run
npx 的原理很简单,就是运行的时候,会到node_modules/.bin路径和环境变量$PATH里面,检查命令是否存在。
由于 npx 会检查环境变量$PATH,所以系统命令也可以调用。
这里有个小技巧,如果你使用yarn或pnpm,在scripts中写npx <cmd>就会使用全局npm去执行这条指令。
npm配置
上面都一直在讲npm如何配置项目,这里也讲讲npm本身应该如何配置。
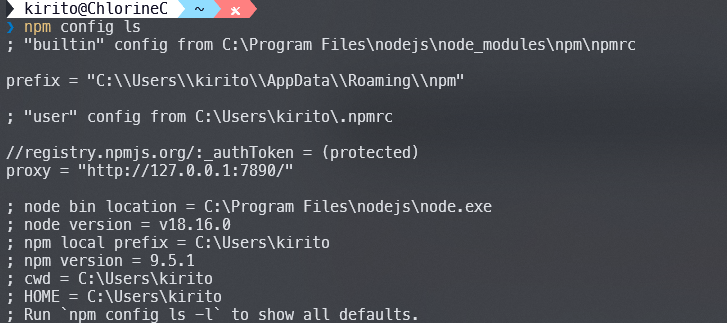
npm的默认配置文件是.npmrc,在~/.npmrc默认有一份用户配置文件,所有项目共享。在运行npm时项目中.npmrc的覆盖优先级高于用户默认值(普通的系统环境变量逻辑)。
使用npm config命令可以读取当前环境下的npm配置文件,我这里没有给项目单独配置.npmrc,因此得到的是全局配置文件(忽略我的7890):
修改配置文件常用的方法有:
- 使用
npm config edit可以直接编辑用户配置文件 - 在项目根目录创建
.npmrc也可以直接覆写设置 - 使用
npm config set <item> <value>修改单项配置
常用的配置项有:
proxy: 代理设置,所有请求都将通过代理请求registry:镜像源设置,替代默认的npm源(详见:npmmirror 镜像站)
说到这里就不得不提到一个Z国特色产品:cnpm,具体功能就是默认将镜像源替换为淘宝源。
虽然免费为国内维护一个高频更新的镜像源确实是功德一件,但个人觉得使用一个没有任何技术特色的包管理器去替代npm实在是没有必要的,如果一定要使用镜像源我个人建议使用registry设置而不是安装cnpm。或者说,我个人更推荐7890方案,如果你还不能精通网络建议重修计网。
发布自己的第一个npm包
最好的学习就是实践,不要认为发布npm包是一个很有门槛的事,这是一个开源、自由的仓库,每个人都可以在上面发布自己的代码。
下面,我们就从0开始使用npm开发一个自己的NodeJS工具库,并发布到npm中。
它的第一个功能就是检测一个用户是否在本地JSON数据库中注册:
- 如果已经注册则返回true,未注册则返回false并添加该用户
- 提供用于添加和删除/清空用户的接口
首先,我们需要在npm官网注册一个账号,验证邮箱并开启2FA,这些过程就不再赘述。
- 创建一个目录,运行
npm init命令,这里推荐命名为yourname-utils(将yourname替换为你的名字,注意为英文)
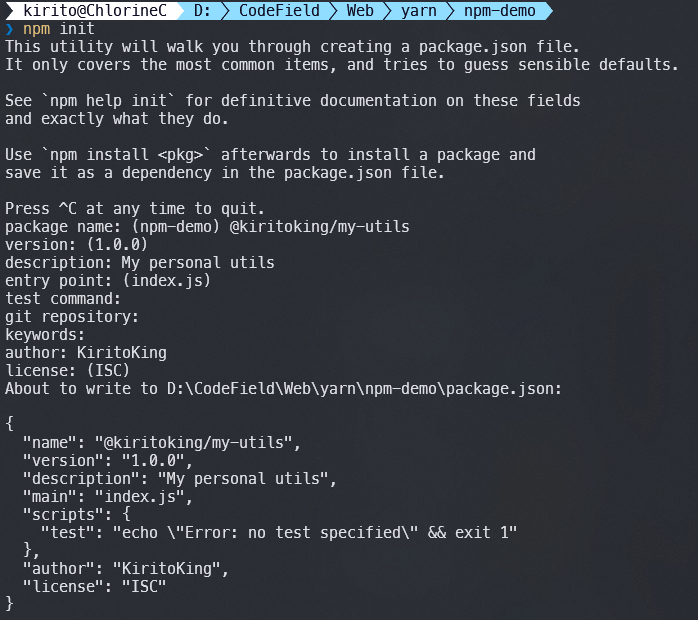
- 初始化完成后会生成一个
package.json,除此之外没有别的文件。此时输入git init初始化Git仓库,然后初始化提交。 - 编写简单的代码来实现功能:分为入口
index.js和功能myDb.js
// myDb.js
const fs = require('fs')
const filePath = './myDb.json'
function check(name) {
if (!name) {
throw new Error('name is required')
}
if (typeof name !== 'string') {
throw new Error('name must be a string')
}
if (!fs.existsSync(filePath)) {
const obj = [name]
fs.writeFileSync(filePath, JSON.stringify(obj))
return false;
}
const data = fs.readFileSync(filePath, 'utf8')
const obj = JSON.parse(data)
if (obj.includes(name)) {
return true
}
obj.push(name)
return false
}
function remove(name) {
if (!name) {
throw new Error('name is required')
}
if (typeof name !== 'string') {
throw new Error('name must be a string')
}
if (!fs.existsSync(filePath)) {
fs.writeFileSync(filePath, JSON.stringify([]))
return false;
}
const data = fs.readFileSync(filePath, 'utf8')
const obj = JSON.parse(data)
const result = obj.filter(item => item !== name)
fs.writeFileSync(filePath, JSON.stringify(result))
}
function clear() {
if (fs.existsSync(filePath)) {
fs.removeSync(filePath)
}
}
module.exports = {
check,
remove,
clear
}
// index.js
const db = require('./myDb.js');
module.exports.db = db;
- 按照上述流程再创建一个项目用于测试,先在原项目运行
npm link,再在测试环境中运行npm link yourname-utils创建软链接 - 在测试环境中编写
index.js
const { db } = require('@kiritoking/my-utils')
const a = db.check('test')
const b = db.check('test')
console.log(a,b) // false, true
- 运行
node index.js,输出如下,并在根目录创建了myDb.json

本地测试通过,现在来上传npm包,就两步,非常简单
npm login登录npm(注意这一步必须是官方源),会打开浏览器来登录

直接运行
npm publish就可以发布该包的当前版本,仍需要打开浏览器认证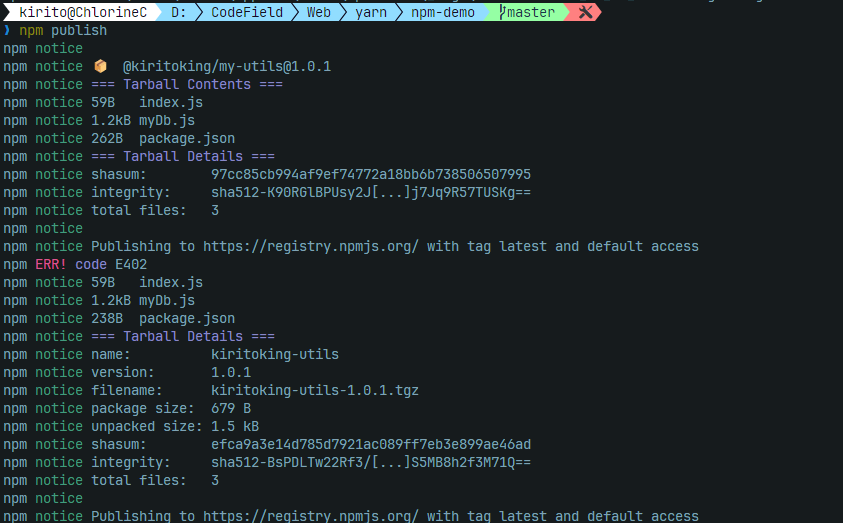
- 在测试环境运行
npm unlink yourname-utils取消软连接,运行npm install yourname-utils从在线安装,再次运行表示成功

npm的没落
在2023年的前端圈,陪我们走过10多年的npm已经垂垂老矣(2010年1月12日发布),逐渐退出历史舞台,越来越多的后起之秀起了替代它的势头。但npm仍是那座历史上的高峰,可以说没有npm就没有前端圈的繁荣,它是这个庞大帝国的基石。
即使有一天,npm已经不再任何场合被推荐使用,它的思想、它的概念仍会在其他包管理器、所有开发者的实践中不断传扬,因此,在2023年的今天,学习npm的历史和思想仍是值得的,这让我们知道为什么会有后面的解决方案,这些解决方案改进了哪些方面,我们才能对项目的工程化有更深刻的认识。就像学习C语言一样,时至今日你可能并不会用大一学习的C语言去开发实用程序,但它教给你的计算机思维将一直伴随你的开发。
更现代的新兵:yarn2和pnpm
尽管npm在迭代中解决了重复依赖、依赖树不确定等诸多问题,但扁平依赖的结构一定是最优解吗?诸如幽灵依赖、难以删除等问题仍萦绕在npm上空。
yarn2提出了PnP(Plug'and'Play,即插即用)结构,直接抛弃了庞大的node_modules目录;pnpm重新搬出了新的嵌套目录+硬链接结构,解决了”幽灵依赖“(项目可以引用自身没有声明的间接依赖)的问题,提高了速度。
这些解决方案将在后面的系列文章中详细解析,它们的出现都撼动了npm的地位。时至2023的今日,它们都是比npm更好的启动新项目的选择,越来越多的项目也选择了拥抱新技术栈和新特性。
corepack: 面向未来
官方介绍来自:nodejs/corepack (github.com)
Corepack is a zero-runtime-dependency Node.js script that acts as a bridge between Node.js projects and the package managers they are intended to be used with during development. In practical terms, Corepack will let you use Yarn and pnpm without having to install them - just like what currently happens with npm, which is shipped by Node.js by default.
Corepack是一个实验性工具,在 Node.js v16.13 版本中引入,它可以指定项目使用的包管理器以及版本。
简单来说,Corepack 会成为 Node.js 官方的内置 CLI,用来管理『包管理工具(yarn、pnpm)』,在管理 Packges 时会直接调用 Corepack 指定的包管理器进行管理,即『包管理器的管理器』。
新版的 pnpm 和 yarn 文档中,都推荐使用 corepack 来安装和管理包管理器,而非全局方式。
需要注意的是:corepack 仅支持yarn和pnpm,并不支持cnpm。
安装并启用 corepack
由于 Corepack 是实验性工具,它并不是默认启动的,需要手动开启,开启后全局有效
- 对于16.13+版本:直接运行
sudo corepack enable(需要管理员/root权限) 对于更低版本:需要手动安装
- 首先,需要卸载已经全局安装的yarn和pnpm
- 然后,全局安装 corepack:
npm i -g corepack
使用 corepack
可以直接使用
yarn、pnpm来进行安装而无需任何配置- 若指令与项目指定的包管理器符合,
corepack会静默下载对应的包管理器并执行你的指令 - 若指令与项目指定的包管理器不一致,
corepack会拒绝你的指令 - 若本地未配置包管理器,
corepack会下载对应的 good-release 版本的包管理器并执行你的指令
- 若指令与项目指定的包管理器符合,
- 需要注意的是,corepack 目前还不支持屏蔽 npm(也就是说你无论你的包管理器指定的是什么,都能运行npm),但node在后续版本中计划逐渐去除 npm集成,改用corepack作为默认的包管理器,放弃npm的太子地位
- 可以在
package.json中指定packageManager字段来指定包管理器,值按[email protected]格式编排,后面可选地附加一个Hash值来确认安全下载,下面的代码就指定了Yarn 3.2.3版本作为包管理器:
{
"packageManager": "[email protected]+sha224.953c8233f7a92884eee2de69a1b92d1f2ec1655e66d08071ba9a02fa"
}
可以使用
corepack prepare [email protected]来下载并安装某个版本的包管理器,也可以直接使用latest下载最新版;增加-activate选项可以将当前下载的版本作为 corepack 的 best-release 版本。- 这个操作可以替代
npm i <package> -g - 比如
corepack prepare yarn@latest就会全局安装最新版yarn,所以我电脑上现在的全局yarn版本就是v3.5.1,pnpm是v8.4.0
- 这个操作可以替代
参考资料
- JS全局变量污染和模块化 - 知乎 (zhihu.com)
- 一文彻底搞懂JS前端5大模块化规范及其区别 - Echoyya、 - 博客园 (cnblogs.com)
- 前端十万个为什么(之一):我们为什么需要npm? - 大唐西域都护 - 博客园 (cnblogs.com)
- Module 的加载实现 - ECMAScript 6入门 (ruanyifeng.com)
- javascript - 深入浅出 ESM 模块 和 CommonJS 模块 - 个人文章 - SegmentFault 思否
- commonjs 与 esm 的区别 - 掘金 (juejin.cn)
- CommonJS规范详解 - 掘金 (juejin.cn)
- CommonJS规范 -- JavaScript 标准参考教程(alpha) (ruanyifeng.com)
- Node.js CommonJS 实现与模块的作用域 - 知乎 (zhihu.com)
- [译] 理解 JavaScript 中的执行上下文和执行栈 - 掘金 (juejin.cn)
- package.json | npm Docs
- 探讨npm依赖管理之peerDependencies - wonyun - 博客园 (cnblogs.com)
- npm scripts 使用指南 - 阮一峰的网络日志 (ruanyifeng.com)
- 超详细 如何发布自己的 npm 包 - 掘金 (juejin.cn)
- npm link 基本使用 - 个人文章 - SegmentFault 思否
标题: 前端包管理器 - npm
作者: ChlorineC
创建于: 2023-06-06 15:05:00
更新于: 2025-01-11 21:00:00
版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
